온디바이스 AI 가속하기: Arm과 Google AI Edge 최적화 엿보기
요약
Arm의 SME2 기술과 Google AI Edge 스택을 활용하여 온디바이스 AI 모델의 성능을 획기적으로 개선하고 개발 과정을 단순화하는 방법을 소개해요.
인사이트
- 하드웨어-소프트웨어 통합 가속: Arm의 SME2(Scalable Matrix Extension 2) 기술이 CPU에 행렬 연산 장치를 직접 통합하고, Google AI Edge 스택(LiteRT, XNNPACK, KleidiAI)이 이를 자동 활용해서 온디바이스 AI 추론 성능을 최대 5배까지 끌어올릴 수 있어요.
- 개발 과정 단순화: Google AI Edge는 PyTorch 모델을 `.tflite`로 변환하고, Model Explorer로 최적화 대상을 시각화하며, AI Edge Quantizer로 양자화하는 등 '변환 → 최적화 → 배포'의 통합된 개발 파이프라인을 제공해서 온디바이스 AI 개발을 정말 쉽게 만들어줘요.
- 실제 성능 향상: Stability AI의 `stable-audio-open-small` 모델을 Arm SME2 기반 디바이스에 배포했더니, 오디오 생성 시간이 2배 이상 단축되고, 메모리 사용량은 4배 줄었으며, 동시에 FP32 버전과 동등한 고품질 오디오를 유지하는 뛰어난 결과를 얻었어요.
왜 중요한가
온디바이스 AI는 사용자의 개인 정보 보호를 강화하고, 네트워크 연결 없이도 AI 기능을 사용할 수 있게 하며, 서버 비용을 절감하는 등 정말 많은 장점이 있어요. 하지만 모바일 기기에서 대규모 모델을 효율적으로 돌리는 건 항상 큰 도전이었죠. Arm의 SME2 같은 전용 하드웨어 가속기와 Google AI Edge 같은 통합 소프트웨어 스택이 합쳐지면, 이제 개발자들이 이 복잡한 문제를 훨씬 쉽게 해결할 수 있게 돼요. 이는 AI 기능을 수십억 대의 스마트폰으로 확장하고, 더 빠르고 개인화된 AI 경험을 대중에게 제공할 수 있는 중요한 발걸음이에요.
2026년 5월 14일
Na Li 엔지니어링 매니저
AI는 단순한 텍스트 상호작용을 넘어서 온디바이스 이미지 및 오디오 생성 같은 풍부한 멀티모달 기능으로 진화하고 있어요. 덕분에 개발자들은 사용자 맞춤형 경험을 만들 수 있게 되었죠. 물론 CPU는 항상 추론을 위한 보편적인 선택지였지만, 엣지 기기에서 복잡하고 큰 모델을 돌리려면 그동안 높은 레이턴시의 CPU 실행과 파편화된 전용 가속기 사이에서 선택해야 하는 문제가 있었어요.
Arm 스케일러블 행렬 확장 2(SME2)는 전용 행렬 연산 장치를 CPU 클러스터에 직접 통합해서 이런 트레이드오프를 없애버렸어요. 이 아키텍처 덕분에 CPU가 고성능 AI 가속기처럼 작동할 수 있게 되었고요. 생성형 AI의 핵심인 행렬 연산 위주의 워크로드에서 최대 5배 빠른 추론 속도를 제공한다고 해요.
Arm 하드웨어에서 온디바이스 AI를 돌리는 건 개발 과정을 단순화하도록 설계된 통합 스택인 Google AI Edge 덕분에 훨씬 더 효율적으로 바뀌었어요. LiteRT는 XNNPACK과 Arm KleidiAI 통합을 통해 런타임에 Arm SME2를 자동으로 활용해요. iGeMM이나 GeMM 같은 수학 연산 집약적인 커널들을 식별하고 선택해서 전문화된 하드웨어 가속을 제공하죠. 배포를 더 쉽게 하기 위해 AI Edge Quantizer는 복잡한 모델 압축을 처리하고, Model Explorer는 성능 저하 지점을 빠르게 찾아 해결할 수 있는 시각적인 지도를 제공해줘요.
이런 통합의 힘은 Stability AI의stable-audio-open-small 모델을 Arm CPU에 완전히 배포하면서 큰 성능 향상을 보여주면서 입증되었어요. 이 블로그 포스트에서는 원래의 부동 소수점 PyTorch stable-audio-open-small 모델을 Arm CPU에서 고성능 가속을 위한 최적화된 혼합 정밀도(FP16/Int8) 구현으로 바꾸는 과정을 자세히 설명해 드릴 거예요.
LiteRT와 Arm SME2 기반 CPU에서 실행되는 Stable Audio Open Small
과제: 모델 품질과 모바일 환경의 균형 맞추기
다양한 모바일 기기에서 단일 프롬프트로 11초짜리 스테레오 클립 같은 고품질 오디오를 직접 생성하려면, 보통 관리 가능한 모델 크기(일반적으로 약 10억 파라미터)가 필요해요. 이런 소규모 언어 모델(SLM) 범위 내에서도 개발자들은 다음과 같은 까다로운 배포 난관에 부딪히곤 해요.
- 복잡성: 수많은 양자화 설정 중에서 최적의 구성을 찾는 건 쉽지 않아요. 게다가 모델 전체 가중치를 단순히 양자화하면 오디오 품질이 심각하게 저하될 수도 있고요.
- 기기 커버리지: 효율적인 CPU 기반 오디오 생성을 위한 길을 여는 것은 단순한 기술적 이정표가 아니에요. 전 세계 스마트폰 시장을 대표하는 수십억 대의 CPU 기반 기기에서 혁신적인 앱들을 확장할 수 있는 기회가 될 수 있어요.
Google AI Edge: PyTorch에서 실리콘까지의 매끄러운 여정
확산 기반 모델을 최적화 목표로 사용해서, 구글 팀은 Google AI Edge 소프트웨어 스택으로 완전한 엔드투엔드 경로를 시연했어요. 아래 그림처럼, 이 시너지는 간소화된 변환(Convert) → 최적화(Optimize) → 배포(Deploy) 파이프라인을 제공하죠.

KleidiAI 최적화가 XNNPACK에 직접 내장되어 있기 때문에 개발자들은 자동으로 특화된 AI 가속 기능을 얻을 수 있어요. 저수준 어셈블리나 커스텀 하드웨어 코드를 작성할 필요 없이, 이 스택이 고수준 모델을 실리콘에 최적화된 실행으로 "번역"하는 역할을 해주거든요.
변환(Convert): LiteRT Torch로 PyTorch 모델을 .tflite로 변환하기
먼저 Stable-audio-open-small 모델의 PyTorch 버전을 AI Edge 생태계로 변환하는 것부터 시작해요. LiteRT-Torch는 PyTorch 모델을 직접 변환할 수 있는 경로를 제공해서, 연구 환경에서 프로덕션 모바일 환경으로 넘어갈 때의 마찰을 최소화해줘요.
import litert_torch
from litert_torch.quantize import quant_config
from litert_torch.generative.quantize import quant_recipe, quant_recipe_utils
# 양자화 형식을 지정합니다.
quant_config_int8 = quant_config.QuantConfig(
generative_recipe=quant_recipe.GenerativeQuantRecipe(
default=quant_recipe_utils.create_layer_quant_dynamic(),
)
)
# 변환을 시작합니다.
edge_model = ai_edge_torch.convert(
model, example_inputs, quant_config=quant_config_int8
)
Python
복사됨
LiteRT-Torch가 실제 작동하는 방식을 보여주는 코드 스니펫은 여기에서 확인할 수 있어요.
최적화(Optimize): Model Explorer와 AI Edge Quantizer로 최적화하기
예전에는 모델의 어떤 레이어가 양자화에 적합한지 일일이 수동으로 확인해야 해서 오류가 발생하기 쉬웠어요.
하지만 이제 Google의 Model Explorer를 사용하면 모델 그래프 전체를 시각화할 수 있어요. 새로운 노드 데이터 오버레이 플러그인은 어떤 연산자가 계산 집약적인지, 아니면 아래 그림처럼 "양자화에 안전한지" 정확히 보여줘요. 이 시각적 검증 덕분에 INT8로 바꿔도 오디오 출력 품질이 저하되지 않을 레이어만 정확히 타겟팅할 수 있게 되었죠.
예를 들어, 확산 단계의 추론 효율성을 높이기 위해 DiT(Diffusion Transformers) 서브모듈에 동적 INT8 양자화를 적용했어요.

각 DiT 트랜스포머 블록에 대해 보고된 중간 차이 비율 오류.
위 스크린샷에서 보듯이, DiT 서브모듈의 모든 레이어가 녹색으로 표시되어 있어요. 이는 DiT 트랜스포머 내부에서 오류 값이 낮다는 것을 의미하죠 (FP32 vs. FP32+INT8). 따라서 동적으로 양자화된 INT8 DiT 서브모듈이 FP32와 비슷한 품질을 낼 것으로 기대할 수 있어요.
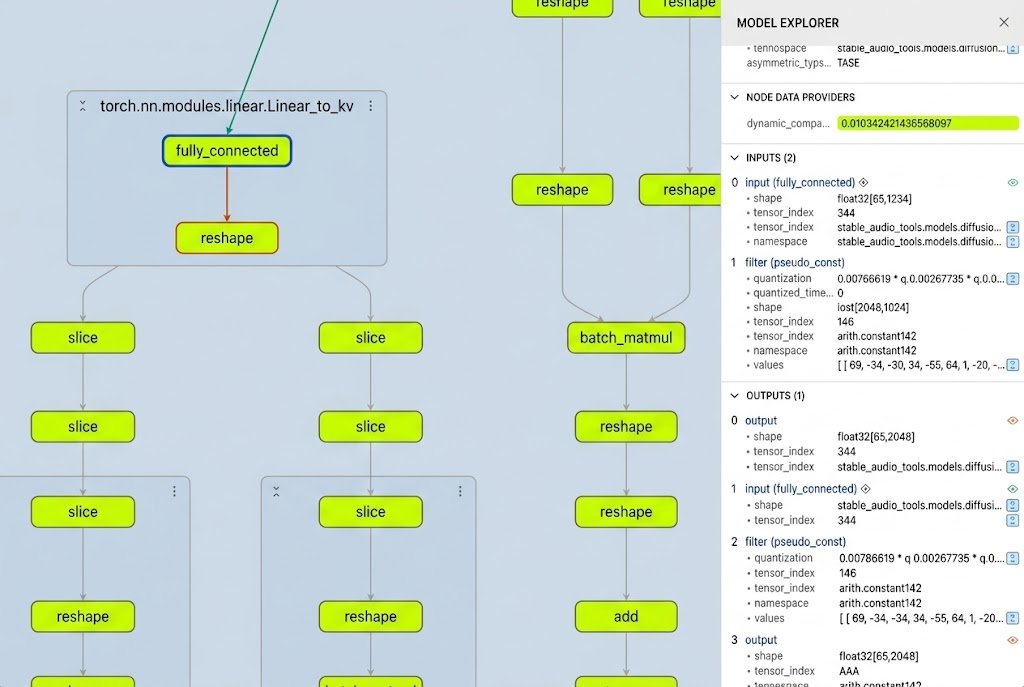
INT8 동적 양자화가 적용된 완전 연결 레이어. "NODE DATA PROVIDERS" 아래에 보고된 오류율은 약 1%예요.
INT8 양자화의 적합성이 확인되자, 구글 팀은 AI Edge Quantizer를 활용해서 모델을 FP32에서 INT8로 최적화했어요.
이 결정 덕분에 DiT 서브모듈에서 3배의 성능 향상과 함께 메모리 사용량이 4배 감소하는 결과를 얻었어요.
fp32_model_path = "./dit_model_fp32.tflite"
dynamic_quant_model_path = "./dit_model_int8+fp32.tflite"
the_recipe = [
dict({
'regex': '.*',
'operation': '*',
'algorithm_key': 'min_max_uniform_quantize',
'op_config': {
'weight_tensor_config': {
'num_bits': 8,
'symmetric': True,
'granularity': 'CHANNELWISE',
'dtype': 'INT',
'block_size': 0,
},
'compute_precision': 'INTEGER',
'explicit_dequantize': False,
'skip_checks': False,
'min_weight_elements': 0
},
})
]
# fp32 tflite 모델과 레시피를 사용하여 양자화 도구를 정의합니다.
qt = quantizer.Quantizer(fp32_model_path, the_recipe)
quant_result = qt.quantize().export_model(dynamic_quant_model_path, overwrite=True)
Python
복사됨
배포(Deploy): XNNPack & KleidiAI를 통한 LiteRT로 고성능 추론하기
마지막 단계는 런타임이에요.
이 양자화된 모델을 안드로이드 모바일 기기에서 LiteRT로 실행하면, CPU 추론을 위해 기본적으로 XNNPACK 델리게이트를 사용해요. XNNPACK이 최신 LiteRT API 내부에 KleidiAI를 직접 통합하고 있어서, 개발자들은 이런 최적화 기능을 자동으로 얻게 되죠. 이 마이크로 커널들은 오디오 모델의 핵심 INT8 및 FP16 행렬 곱셈이 CPU에서 최고의 효율로 실행되도록 보장해줘요.
아래는 CompiledModel API를 사용해서 LiteRT 추론이 C++로 어떻게 구현되는지를 보여주는 대표적인 코드 스니펫이에요. 이 가이드에서는 안드로이드™ 기기나 macOS®에서 LiteRT로 오디오 생성 앱을 실행하는 방법에 대한 지침을 제공하고 있어요.
#include "litert/cc/litert_compiled_model.h"
#include "litert/cc/litert_environment.h"
#include "litert/cc/litert_tensor_buffer.h"
// 1. LiteRT 환경 초기화
auto env = litert::Environment::Create({}).value();
// 2. .tflite 파일에서 CompiledModel 생성
// 하드웨어 가속 (예: KleidiAI를 통한 SME2)은 자동으로 처리됩니다.
auto compiled_model = litert::CompiledModel::Create(
env, "autoencoder_model.tflite", litert::HwAccelerators::kCpu).value();
// 3. 입력 및 출력 버퍼 준비
auto autoencoder_inputs = compiled_model.CreateInputBuffers().value();
auto autoencoder_outputs = compiled_model.CreateOutputBuffers().value();
// 4. 입력 데이터 작성 (예: 랜덤 노이즈 또는 조건부 임베딩)
auto auto_in_lock_and_ptr = scoped_lock<float>(autoencoder_inputs[0],
litert::TensorBuffer::LockMode::kWrite);
// 입력 채우기
// 5. 추론 실행
compiled_model.Run(autoencoder_inputs, autoencoder_outputs);
// 6. 출력 버퍼에서 생성된 오디오 파형 접근 및 읽기
auto auto_out_lock_and_ptr = scoped_lock<const float>(autoencoder_outputs[0], litert::TensorBuffer::LockMode::kRead);
// 출력 읽기
C++
복사됨
결과: 더 빠르고, 작고, 고품질 오디오를 적은 리소스로 생성해요
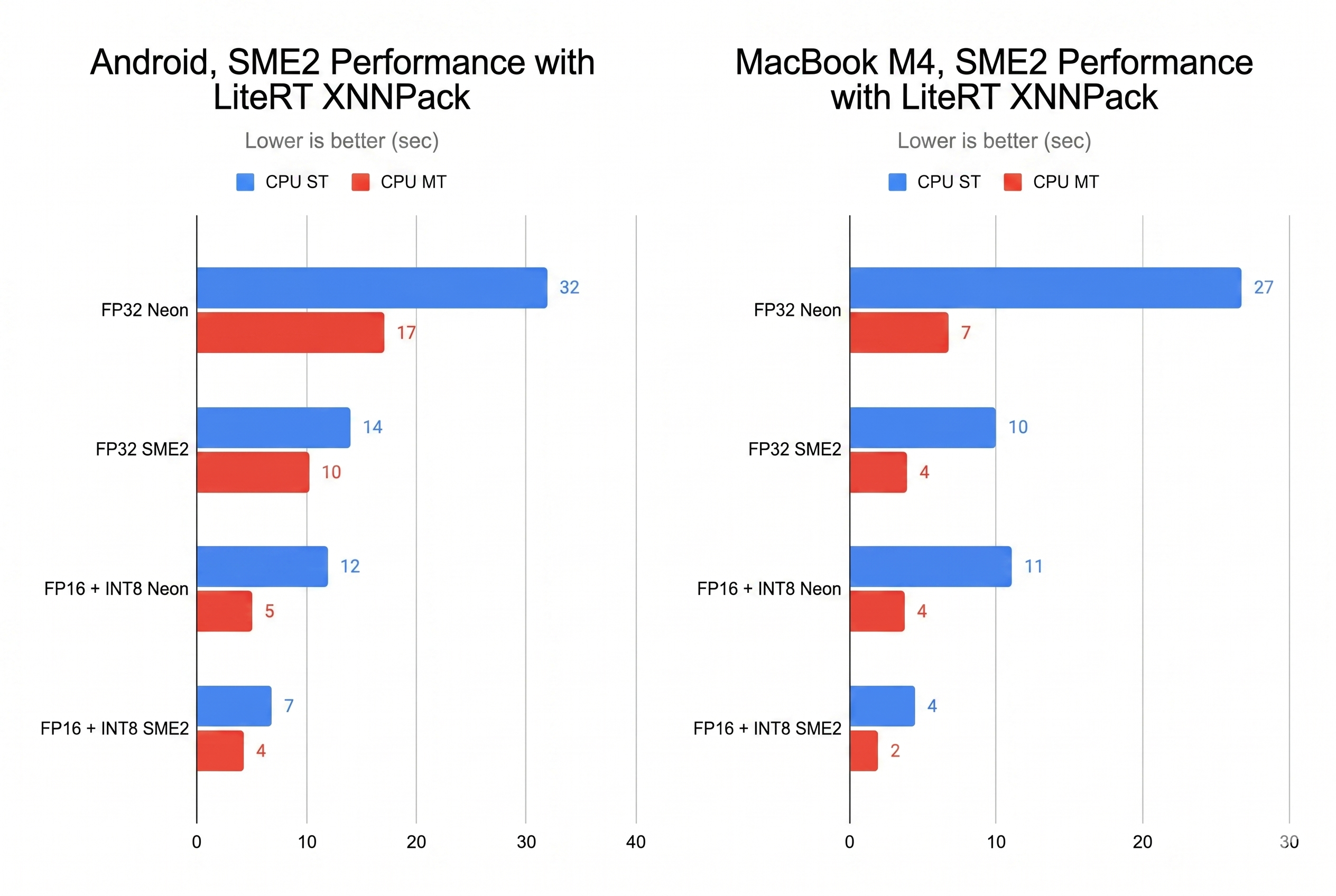
이제 이전 섹션에서 만든 양자화된 FP16/INT8 모델을 가지고, 원래 FP32 Stable Audio Open Small 모델과 KleidiAI로 최적화된 FP16 + INT8 모델의 CPU 단일 스레드 및 멀티 스레드(MT) 성능을 SME2 기반 안드로이드 기기와 Apple MacBook M4에서 벤치마킹했어요.
- 속도: 오디오 생성 시간이 2배 이상 줄어들었어요. Apple MacBook M4에서는 10초에서 4.3초로, Arm SME2 기반 안드로이드 기기에서는 1스레드 기준으로 14초에서 6.6초로 단축되었죠.
- 메모리: DiT 서브모델 크기가 약 4배 감소해서, 추론 중 RAM 사용량이 크게 줄었어요.
- 품질: 가장 중요한 점은, 생성된 오디오가 FP32 버전과 지각적으로 동등한 품질을 유지했다는 거예요.
위 막대 그래프에서 보듯이, SME2는 신호 처리 작업에 특화된 NEON 명령어 세트보다 2배 이상의 성능 향상을 제공해요. 단일 코어만으로도 11초 분량의 오디오를 8초 이내에 생성할 수 있는데, 이는 사용자 경험 관점에서도 충분히 허용할 만한 수준이에요.
더 자세히 알고 싶으신가요?
이런 최적화 기능들은 지금 바로 개발자들이 사용할 수 있어요. Google AI Edge 도구와 KleidiAI 가속 LiteRT를 사용해서 바로 실험을 시작해 보세요.
지금 바로 실험해 보세요
Arm의 샘플 저장소를 살펴보시면 Stable Audio Open의 완전한 엔드투엔드 여정을 경험할 수 있어요.
- 변환(Convert): LiteRT-torch를 사용해서 PyTorch 모델을 AI Edge 생태계로 가져오세요.
- 최적화(Optimize): Model Explorer와 AI Edge Quantizer를 포함한 Google AI Edge 도구를 사용해서 엣지 기기에 맞게 모델을 시각화하고 압축하세요.
- 배포(Deploy):: Arm 기반 스마트폰과 노트북에서 Stable Audio Open Small 샘플 코드를 실행해서 Arm SME2 가속이 실제로 어떻게 작동하는지 직접 확인해 보세요.
개발자 자료
- LiteRT 다운로드: 최신 OSS 또는 Maven 버전에 접속해서 Arm KleidiAI 마이크로 커널로 강력해진 최신 XNNPACK 엔진을 사용하고 있는지 확인하세요.
- Google AI Edge 문서: 모델 변환 및 하드웨어 위임에 대한 포괄적인 개발 가이드를 보려면 LiteRT 문서를 방문해 보세요.
- Arm 개발자 포털: 최신 Armv9-A CPU에서 최대 처리량을 얻는 방법을 이해하려면 Arm SME2와 KleidiAI에 대해 더 알아보세요.
감사의 말씀
Arm: Adnan Alsinan, Anitha Raj, Aude Vuilliomenet, Bala Gattu, Declan Cox, and Gian Marco Iodice
Stability AI 크레딧: 이 게시물은 Stability AI Community License에 따라 출시된 Stability AI의 Stable Audio Open Small 모델을 사용합니다. 오디오 샘플은 LiteRT & Arm Kleidi AI를 통해 테스트 기기에서 실행되는 모델을 사용하여 생성되었습니다.
Google: Advait Jain, Andrei Kulik, Changmin Sun, Cormac Brick, Dillon Sharlet, Eric Yang, Jinjiang Li, Jing Jin, Lu Wang, Maria Lyubimtsev, Meghna Johar, Pedro Gonnet, Ram Iyengar, Sachin Kotwani, Terry (Woncheol) Heo, Vitalii Dziuba
다음