클로드 에이전트, 다양한 제품에서 안전하게 격리하기
요약
강력한 AI 에이전트인 클로드를 다양한 제품에 안전하게 배포하기 위해 앤트로픽이 어떤 격리 전략과 보안 방안을 적용하고 있는지 자세히 설명하는 글이에요.
인사이트
- 모델 계층 방어는 확률적이라 한계가 있으니, 샌드박스나 VM 같은 환경 계층에서의 강력한 격리(Containment)가 에이전트 보안의 핵심이자 마지막 보루 역할을 해요.
- 사용자의 수동 승인은 '승인 피로' 때문에 완벽하지 않고, 사용자 유형(개발자 vs 비기술직)에 따라 필요한 보안 수준과 격리 전략이 달라져야 해요.
- 하이퍼바이저나 컨테이너 런타임처럼 검증된 기존 보안 기술은 튼튼하지만, 자체적으로 만든 프록시나 설정 파싱 같은 커스텀 컴포넌트에서 의외의 취약점이 발생하는 경우가 많으니 주의해야 해요.
왜 중요한가
AI 에이전트가 점점 더 강력해지고 일상 업무에 깊이 스며들면서, 오작동 시 발생할 수 있는 피해 범위(blast radius)도 커지고 있어요. 이 글은 앤트로픽이 클로드 에이전트를 안전하게 배포하면서 얻은 실질적인 보안 노하우를 공유하는데요, 이는 AI 기술의 잠재력을 최대한 활용하면서도 위험을 최소화하는 데 필수적인 지침이 될 거예요.
개발자 뉴스레터 받아보기
제품 업데이트, 사용 방법, 커뮤니티 스포트라이트 등 다양한 소식을 매달 이메일로 보내드려요.

1년 전만 해도 앤트로픽 팀은 클로드에게 사내 서비스를 중단시킬 정도의 접근 권한을 주는 건 상상조차 못 했을 거예요. 하지만 지금은 이런 수준의 접근 권한이 일상적이고, 덕분에 앤트로픽 개발자들은 훨씬 더 생산적으로 일하고 있어요. 이런 배포의 위험은 두 가지 요소로 나눌 수 있는데요, 하나는 실패 가능성이고, 다른 하나는 실패했을 때 발생할 수 있는 피해 규모예요. 안전 장치와 모델 훈련 덕분에 첫 번째 요소는 꾸준히 줄어들고 있지만, 두 번째 요소, 즉 이론적인 피해 범위(blast radius)는 클로드의 기능과 접근 권한이 확장될수록 계속 커지고 있어요. 하지만 에이전트가 한때 사람이나 팀 전체가 해야 했던 일을 처리할 수 있게 되면서, 배포하지 않았을 때의 기회비용이 너무 커져서 위험-보상 계산이 도입 쪽으로 기울고 있어요. 물론, 제품을 안전하게 만들 수 있다는 전제 하에서요. 결국, 엔지니어링 질문은 '어떻게 피해 범위를 제한할 것인가?'로 귀결되는 거죠.
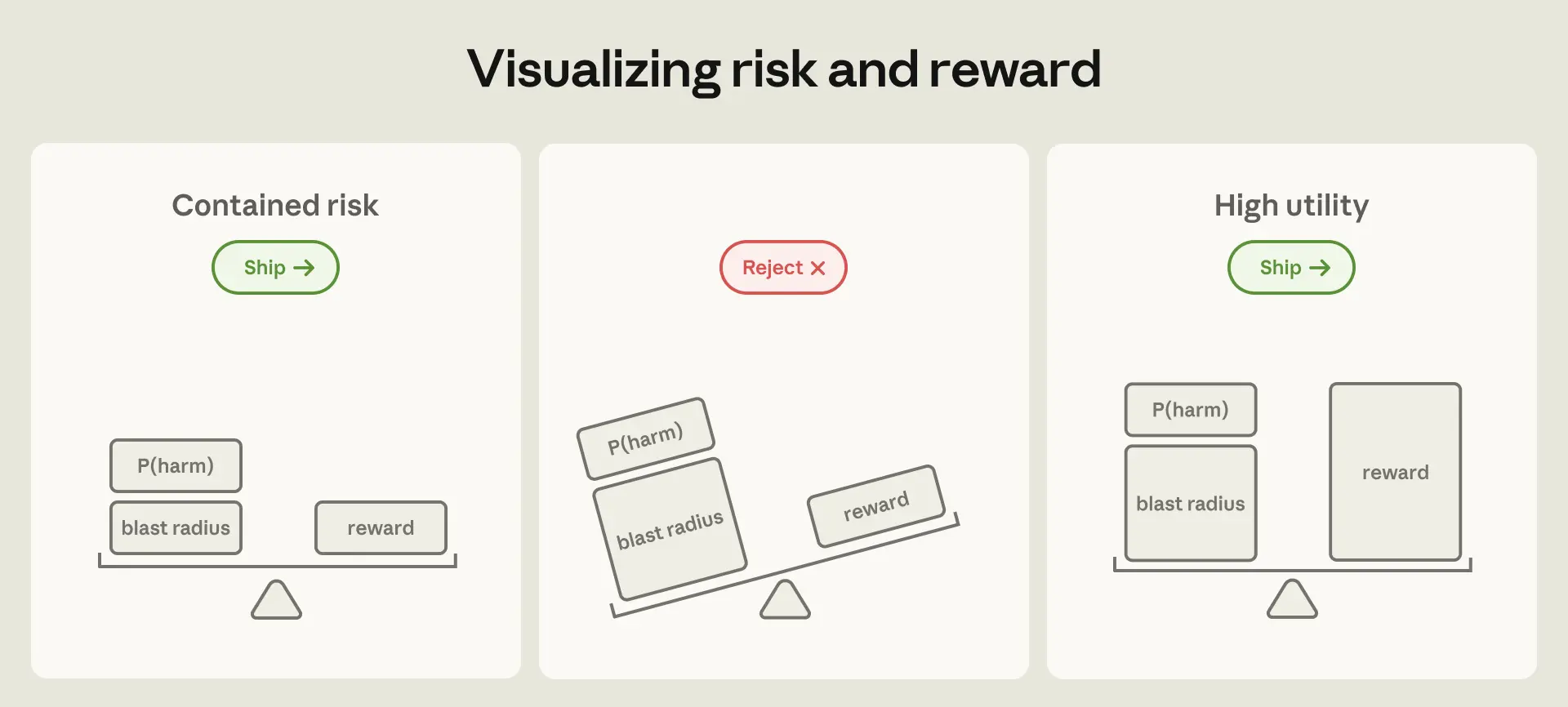
크게 두 가지 방법이 있어요.
첫 번째는 '인간 개입(Human-in-the-loop)'을 통해 에이전트의 행동을 감독하는 거예요. 클로드 코드(Claude Code)는 이전에 에이전트가 의도치 않은 작업을 수행하지 못하도록 매 단계마다 사용자에게 허락을 구했었죠. 이론적으로는 통하는 방법이지만, 앤트로픽 팀은 이 방식이 허점이 있다는 걸 발견했어요. 앤트로픽 팀의 원격 측정 데이터에 따르면, 사용자들은 권한 요청의 약 93%를 승인했어요. 사용자들이 승인 요청을 더 많이 볼수록, 각 요청에 대한 주의력은 떨어지고 시간이 지남에 따라 감독에 훨씬 덜 신중해지는 거죠. 최근 앤트로픽 팀은 이런 승인 피로를 줄이기 위해 더 안전한 승인을 자동화하는 클로드 코드 오토 모드(Claude Code auto mode)를 만들었어요. 하지만 여전히 취약점은 남아있는데요, 어떤 확률적 방어든 놓치는 경우가 0%일 수는 없거든요.1
피해 범위를 제한하는 두 번째 접근 방식이자, 이 글의 주요 초점은 바로 '격리(Containment)'예요. 에이전트가 무엇을 하는지 감독하는 대신, 샌드박스, 가상 머신, 송신 제어(egress control) 등을 통해 접근 경계를 강제해서 에이전트가 무엇을 할 수 있는지를 감독하는 거죠. 앤트로픽 엔지니어링 팀이 가장 많은 노력을 기울인 부분이 바로 이곳이고, 가장 놀라운 보안 실패들이 발생했던 곳이기도 해요.
지난 2년간 앤트로픽 팀은 세 가지 주요 에이전트 제품을 출시했어요: claude.ai, Claude Code, 그리고 Claude Cowork요. 각 제품은 서로 다른 사용자층을 대상으로 하므로, 각기 다른 격리 아키텍처가 필요했어요. 이 글에서는 어떤 방식이 효과적이었고, 어떤 점이 실패했으며, 에이전트 보안에 대해 앤트로픽 팀이 그동안 무엇을 배웠는지 공유할게요.
에이전트의 보안 위험은 크게 세 가지 범주로 나눌 수 있어요:
**사용자 오용: **사용자가 악의적으로 또는 부주의하게 에이전트에게 해로운 일을 지시하는 경우예요. 여기에는 성가신 확인 절차를 우회하도록 요청하거나, 이해하지 못하는 파괴적인 명령을 실행하게 하거나, 의도적인 해를 끼치도록 지시하는 모든 경우가 포함돼요.
**모델 오작동: **에이전트가 누구도 요청하지 않은 해로운 행동을 하는 경우예요. 앤트로픽 모델이 개선되면서 대부분의 행동 평가에서 더욱 정렬(aligned)되었지만, 이것이 위험이 반드시 줄어든다는 의미는 아니에요. 능력이 떨어지는 모델은 상황을 오해하고 명백한 오류를 저지를 가능성이 더 커요. 더 유능한 모델은 실수가 적지만, 예상치 못한 방식으로 목표를 달성하는 데도 더 뛰어나며, 종종 아무도 기록해두지 않은 제한 사항을 우회하는 방법을 찾기도 해요.
앤트로픽 팀은 클로드 모델이 작업을 완료하기 위해 샌드박스를 “친절하게” 탈출하는 경우를 봤고요, 코딩 테스트 정답을 찾기 위해 Git 기록을 조사하거나, 벤치마크가 실행 중인 것을 스스로 알아내어 답변 키를 해독하는 경우도 있었어요. 각 모델은 때때로 예상치 못한 방식으로 활용되는 새로운 기능들을 가지고 오죠.
**외부 공격자: **에이전트가 도구, 파일 또는 네트워크 접근과 같은 외부 경로를 통해 공격받는 경우예요. 이 범주에는 프롬프트 인젝션(Prompt Injection)과 에이전트의 런타임, 오케스트레이션 계층, 또는 프록시에 대한 전통적인 공격이 모두 포함돼요.
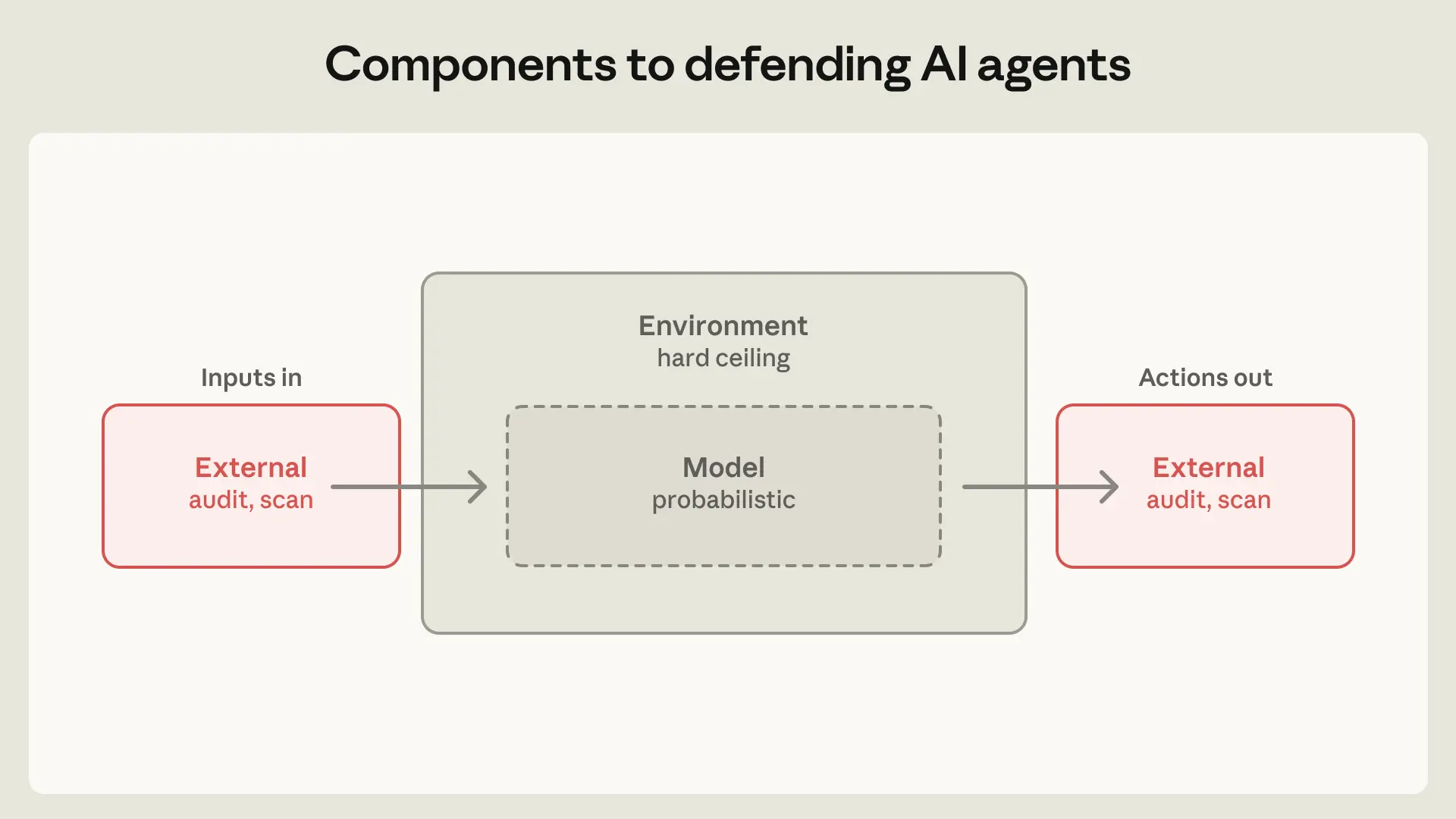
격리 및 방어 시스템을 구축할 때, 앤트로픽 팀은 세 가지 주요 구성 요소에 방어책을 적용하고 있어요:
에이전트가 실행되는 환경: 프로세스 샌드박스, VM, 파일 시스템 경계, 송신 제어(egress control) 등을 통해 에이전트가 어디서 어떻게 행동할 수 있는지 제한해요. 목표는 에이전트가 도달할 수 있는 범위에 대해 엄격한 경계를 설정하는 거예요. 예를 들어, 자격 증명(credentials)이 샌드박스에 들어가지 않으면, 사용자 때문이든, 모델이 “창의적인” 경로를 찾았든, 공격자 때문이든 상관없이 유출될 수 없어요.
깐깐한 경계는 또한 감독을 덜 엄격하게 할 수 있다는 의미이기도 해요. 클로드 코드의 레퍼런스 개발 컨테이너는 에이전트가 작업별 승인 없이도 감독받지 않고 실행될 수 있도록 정확히 존재하는 거죠.
에이전트가 참고하는 모델: 여기에는 시스템 프롬프트, 분류기(classifier), 프로브, 그리고 훈련 수정 등이 포함돼요. 모델은 확률적이기 때문에, 이런 메커니즘은 에이전트가 어떤 행동을 하는 경향이 있는지만 형성할 뿐, 이론적으로 할 수 있는 것을 완전히 막지는 못해요.
이런 방어책들은 강력해요. 프롬프트 인젝션에 대한 취약점을 테스트하는 Gray Swan의 Agent Red Teaming 벤치마크에서, 클로드 Opus 4.7은 단일 시도에서 공격 성공률을 약 0.1%로 유지했고, 100번의 적응형 시도 후에는 약 5~6%를 기록했어요. 클로드 코드 오토 모드는 실행 전에 약 83%의 과도한 행동을 탐지해요. 하지만 최고 수준의 방어책을 사용하더라도 모델 계층에서의 보호는 결코 100% 효과적일 수 없어요. 그래서 모델 계층만으로는 충분하지 않은 거죠.
에이전트가 도달할 수 있는 외부 콘텐츠: MCP 서버, 타사 플러그인, 웹 검색 도구는 모두 앤트로픽 팀이 통제할 수 없는 출처에서 에이전트의 컨텍스트로 콘텐츠를 공급해요. 감사를 거친 커넥터가 감사를 거친 데이터와 동일한 것은 아니에요. 예를 들어, GitHub 커넥터는 악성코드 검사를 통과했더라도 오염된 README 파일을 모델의 컨텍스트로 직접 로드할 수 있어요. 도구 권한을 세분화하여 제한하면 피해 범위를 줄이는 데 도움이 될 수 있어요. 예를 들어, 읽기 전용 DB 접근 권한이 있는 에이전트는 프로덕션 환경에 쓰기 작업을 하는 에이전트보다 훨씬 더 광범위하게 배포될 수 있죠.
방어책은 서로 중첩되고 보완되어야 해요. 환경 방어책을 사용할 수 없을 때는 모델 계층이 그 역할을 대신해야 하죠(이것이 바로 클로드 코드의 오토 모드가 설계된 이유예요). 로컬에서는 환경 및 모델 방어책이 악의적인 도구 출력을 막을 수 있지만, 도구의 기능과 접근 권한을 제한함으로써 체인의 더 높은 곳에서도 방어책을 추가할 수 있어요.
환경 계층에 초점을 맞춰, 앤트로픽 팀은 세 가지 격리 패턴과 이들이 각 클로드 플랫폼(claude.ai, Claude Code, Cowork)에 어떻게 맞춰져 있는지 설명할게요. 앤트로픽 팀은 에이전트에게 필요한 기능과 사용자로부터 요구되는 개입 수준 사이의 균형을 찾으면서, 각 설계를 점진적으로 발전시켜 나갔어요.
claude.ai는 채팅 인터페이스로 가장 잘 알려져 있지만, 코드도 작성하고 실행하며, 파일을 생성하고, 커넥터를 호출하기도 해요. claude.ai 내에서 클로드가 코드를 실행할 때는 격리된 인프라의 gVisor 컨테이너 안에서 실행돼요. 에이전트는 전적으로 서버 측에서 작동하며, 로컬 머신에서는 어떤 코드도 실행되지 않고, 파일 시스템은 일시적(세션별)이에요. 피해 범위는 최소화되지만, 클로드가 할 수 있는 일의 한계도 명확해요. 영구적인 작업 공간이 없고 사용자의 파일 시스템에 접근할 수 없거든요.
이 때문에 claude.ai는 더 전통적인 위협 모델의 영향을 받아요. 앤트로픽 팀은 에이전트로부터 사용자 머신을 보호하는 게 아니라, 앤트로픽 팀의 인프라와 각 테넌트(tenant)를 서로로부터 보호하는 거죠. claude.ai 출시 전 작업은 네트워크 구성, 내부 서비스 인증, 오케스트레이션과 같은 전통적인 보안 작업에 집중되었어요.
그 작업은 보안의 가장 오래된 교훈을 다시금 확인시켜줬어요. 가장 약한 계층은 바로 '스스로 구축한 부분'이라는 거죠. gVisor와 seccomp는 에이전트 AI가 존재하기 훨씬 전부터 막강한 적들에게 맞서 강화되어 왔기 때문에, 검토 노력은 그 주변에 앤트로픽 팀이 새로 구축한 부분에 집중되었어요. 앤트로픽 팀의 커스텀 프록시가 가장 중요한 사고에서 문제가 된 부분이기도 하므로, 이 이야기는 나중에 다시 다룰게요.
Claude Code는 사용자의 컴퓨터에서 실행되며, 파일 시스템, 셸, 네트워크에 접근할 수 있어요. 이런 접근 권한 없이는 코딩 에이전트의 유용성이 제한되기 때문에, 안전하게 접근 권한을 부여하는 방법을 찾는 것이 필수적이에요.
한 가지 접근 방식은 인간 개입(human-in-the-loop)에 의존하는 거예요. 클로드 코드의 경우, 평균 사용자가 코딩 환경에 익숙한 개발자이기 때문에 이것이 실행 가능한 해결책일 뿐이에요. 그들은 Bash를 읽을 수 있고, rm -rf가 무슨 일을 하는지 이해하며, 일주일에 몇 번씩 신뢰할 수 없는 출처에서 npm install을 실행하곤 하죠. 이 모든 것은 "이것을 허용하시겠습니까?"라는 대화 상자가 나타날 때, 에이전트가 하려는 일과 관련된 위험을 정확하게 평가할 전문 지식을 가지고 있을 가능성이 매우 높다는 의미예요. 이를 고려하여, 클로드 코드는 가장 간단한 방어책으로 출시되었어요. 읽기 허용, 쓰기, Bash, 네트워크 접근에는 승인 필요.
하지만 앞서 언급했듯이, 승인 피로는 몇 주 안에 나타났어요. 아이러니하게도, 이는 원래 감독을 제공하도록 설계된 기능이 오히려 반대 효과를 가져올 수 있다는 것을 의미했어요. 일부 사용자들은 단순히 주의를 기울이지 않게 될 수 있었죠. 부주의한 승인을 완화하기 위한 첫 단계로, 앤트로픽 팀은 OS 수준의 샌드박스(macOS의 Seatbelt, Linux의 bubblewrap)를 출시해서 경계를 강화했어요. 읽기는 허용되고, 쓰기는 작업 공간 내에서 허용되지만, 네트워크는 기본적으로 차단되죠. 샌드박스 내에서 에이전트는 거의 중단 없이 실행돼요. 그 결과 권한 요청이 84% 감소했고, 앤트로픽 팀은 런타임을 오픈 소스화해서 경계가 감사 가능하도록 만들었어요.
앤트로픽 팀의 익명화된 사용 데이터에 따르면, 숙련된 사용자들은 신규 사용자보다 약 두 배 자주 자동 승인을 하지만, 실행 도중 에이전트를 더 자주 중단시키기도 했어요. 개별 단계를 일일이 승인하기보다는, 숙련된 사용자들은 에이전트가 잘못된 방향으로 갈 때만 감독하는 경향이 있는 거죠. 이것이 사람들이 에이전트와 일하는 방식의 자연스러운 진화일 수도 있지만, 역시 허점이 있어요. 사용자가 애초에 이런 이탈을 알아챌 만큼 기술적이고 주의 깊어야 한다는 전제가 있거든요. 모델 기능이 향상되고 에이전트가 점점 더 복잡한 Bash 스크립트를 작성하기 시작하면, 이런 이탈을 알아채기는 더욱 어려워져요. 그리고 사용자들이 멀티 에이전트 시스템으로 이동함에 따라, 이 접근 방식은 효과적인 감독 전략이 될 가능성이 훨씬 줄어들어요.
2025년 중반부터 2026년 1월 사이에, 앤트로픽 팀은 책임 있는 공개 프로그램을 통해 클로드 코드의 취약점에 대한 보고를 받았어요. 이 중 세 가지는 사용자가 어떤 것에도 동의하기 전에 실행되는 코드를 악용했죠. 이것이 어떻게 가능한지 이해하려면 가장 직접적인 사례를 생각해 보세요. 개발자가 풀 리퀘스트를 검토하기 위해 저장소를 복제했는데, 해당 저장소에 훅(hook)을 정의하는 .claude/settings.json 파일이 포함되어 있는 거예요. 클로드 코드는 시작 시 프로젝트 설정을 읽기 때문에(표준 "이 폴더를 신뢰하시겠습니까?" 프롬프트를 제시하기 전에), 공격자가 작성하고 커밋한 훅이 자동으로 실행될 수 있었던 거죠. 나머지 사례들도 구조적으로 유사했어요. 아직 신뢰하지 않은 디렉토리의 입력이 신뢰 경계가 설정되기 전에 파싱되는 형태였죠.
각 경우의 해결책은 동일한 형태였어요. 프로젝트 로컬 구성의 파싱 및 실행을 사용자가 신뢰 프롬프트를 수락한 후로 연기하는 거죠. 유사한 것을 만들고 있다면, 프로젝트 열기, 구성 로드, 로컬 호스트 리스너를 인터넷에서 들어오는 모든 요청과 동일하게 취급하세요. 로컬에서 발생하고 사용자가 동의하기 전에 도착한다고 해서 묵시적으로 신뢰해서는 안 돼요.
2026년 2월, 통제된 내부 레드팀(red-team) 훈련 중에 한 연구원이 악의적인 프롬프트를 사용하여 직원을 성공적으로 피싱(phishing)해서 클로드 코드를 실행하도록 만들었어요. 피싱은 일반적인 협업처럼 보였죠. "이것 좀 실행해 줄 수 있어?"라는 이메일과 바로 붙여넣을 수 있는 프롬프트가 첨부되어 있었어요. 프롬프트 자체는 일상적인 작업 지시처럼 보였고요. 하지만 설정 단계 어딘가에, 클로드에게 ~/.aws/credentials를 읽고, 내용을 인코딩한 다음, 외부 엔드포인트로 POST하도록 은근슬쩍 요청하는 내용이 담겨 있었어요. 그 프롬프트를 25번 재시도했을 때, 클로드는 24번이나 데이터 유출을 완료했어요.
이건 직접적인 프롬프트 인젝션이었어요. 공격자의 지시가 도구 출력이나 가져온 콘텐츠를 통하지 않고 사용자를 통해 전달된 거죠. 앤트로픽 팀의 모델 계층 방어는 사용자 의도에 초점을 맞추는데, 사용자가 직접 명령을 입력할 때는 분류기가 포착할 만한 이상한 점이 없거든요. 같은 스크립트를 받은 인간 계약직 직원도 똑같이 했을 거예요.
이런 상황에서 유일하게 효과적인 방어책은 바로 환경이에요. 구체적으로는 의도와 상관없이 POST를 차단하는 송신 제어(egress control)와 ~/.aws에 애초에 접근하지 못하게 하는 파일 시스템 경계인 거죠.
(앤트로픽 팀이 내부 슬랙에서 토론을 위해 이 작동하는 프롬프트를 공유했을 때, 누군가 일부 내부 에이전트가 슬랙을 읽는다는 점을 지적했어요. 악성 페이로드가 이제 환경에 떠다니게 된 거죠. 그래서 앤트로픽 팀은 스레드에 카나리 문자열을 추가해서 만약 어떤 에이전트라도 이를 가져가면 알아챌 수 있도록 했어요. 에이전트가 모든 것을 읽는 세상에서는 조사 도구조차도 공격 표면이 되는 거죠.)
Claude Cowork는 사용자가 선택한 작업 공간 폴더에 접근 권한을 가지고 사용자 데스크톱에서 실행돼요. 이 플랫폼은 소프트웨어 엔지니어링이 아닌 일반 지식 작업을 위해 만들어졌기 때문에, 일반 사용자는 Bash에 능숙할 가능성이 훨씬 적어요.
결과적으로, 인간 개입 샌드박스 전략은 그대로 적용하기 어려울 수 있어요. 비기술직 지식 근로자에게 find . -name "*.tmp" -exec rm {} \;와 같은 Bash 주문을 판단하라고 기대해서는 안 되거든요. 예외를 승인하는 데 일반 사용자가 가지고 있지 않은 전문 지식이 필요하다면, 관리자는 절대적이고 항상 켜져 있는 경계를 설정해야 해요.
이를 위해 Claude Cowork의 첫 번째 버전은 플랫폼 공급업체의 하이퍼바이저(macOS의 Apple Virtualization 프레임워크, Windows의 HCS)를 사용하여 전체 가상 머신(VM) 내에서 실행되었어요. VM은 자체 Linux 커널, 자체 파일 시스템, 자체 프로세스 테이블을 가지고 있죠. 사용자가 선택한 작업 공간과 .claude 폴더만 마운트되고, 호스트의 다른 어떤 것도 보이지 않아요. 자격 증명은 호스트의 키체인에 남아있고 게스트 머신에 들어가지 않아요. 이 설계는 클로드가 어떤 시점에서든 정렬되지 않은 방식으로 행동할 가능성에 대비하여 보호해요. 손상된 클로드도 작업 공간 폴더 내부를 손상시킬 수 있지만, 이 아키텍처는 클로드가 오직 그것에만 도달할 수 있도록(사용자가 커넥터를 추가하기 전까지는), 그리고 사용자가 거기에 무엇이 마운트되는지 제어하도록 설계되었어요.
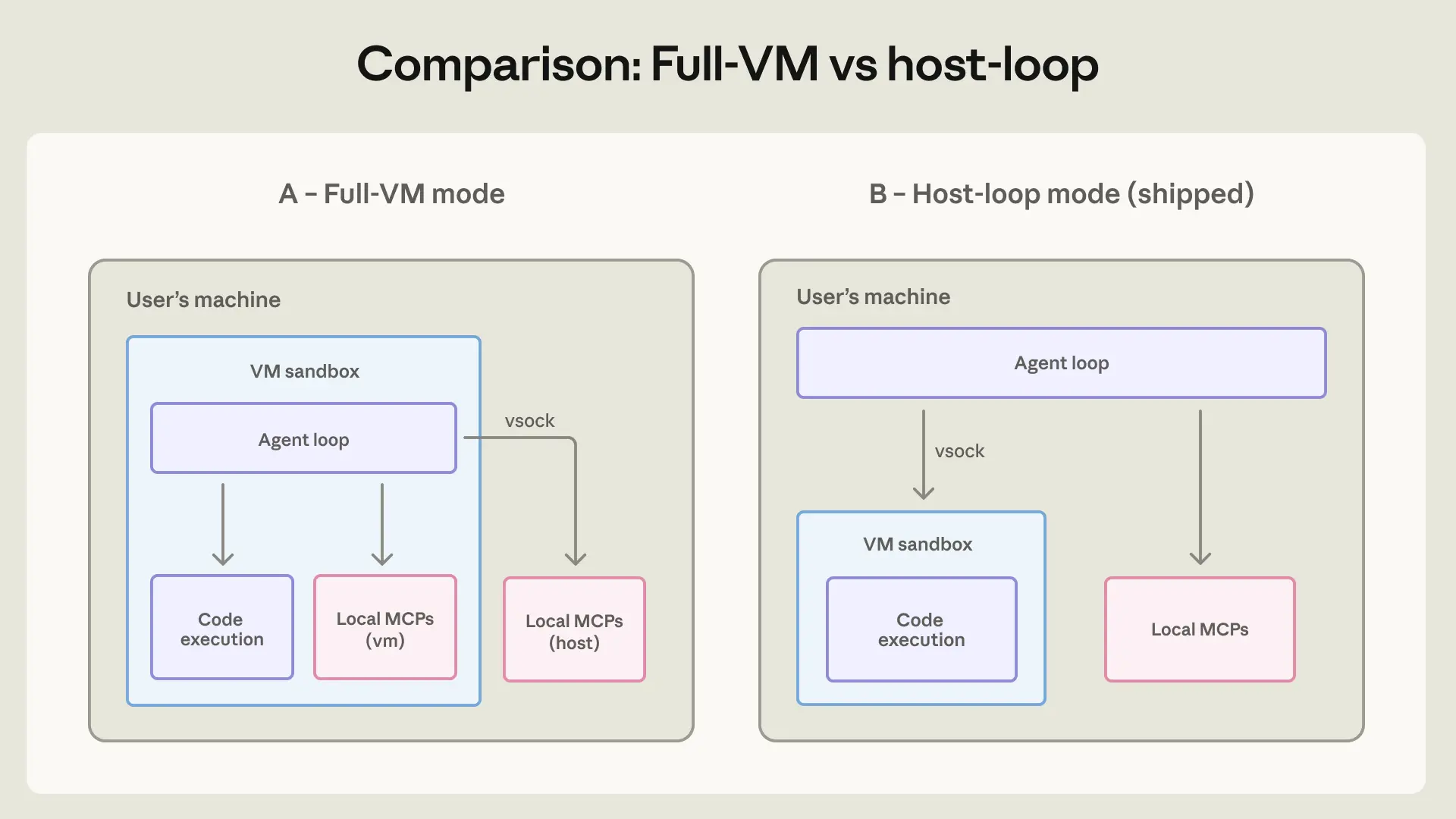
원래 아키텍처, 즉 앤트로픽 팀이 전체 VM 모드(full-VM mode)라고 부르는 방식에서는 에이전트 루프 자체가 게스트 내부에서 실행되었어요. 그래서 클로드는 샌드박스에 있다는 것을 인지하지 못하는 일반 Linux 사용자처럼 작동했죠. 이는 특권 프로세스가 샌드박스 밖에 앉아 명령별로 샌드박스 적용 여부를 결정하는 클로드 코드와는 대조적이에요. 설득력 있는 프롬프트 주입이나 피로로 인한 승인 클릭이 해당 프로세스에 샌드박스 외부에서 무언가를 실행하도록 만들 수 있거든요. 여기서는 탈출 키를 쥐고 있는 외부 프로세스가 없었기 때문에, 예외를 부여할 권한이 있는 구성 요소도 없었어요.
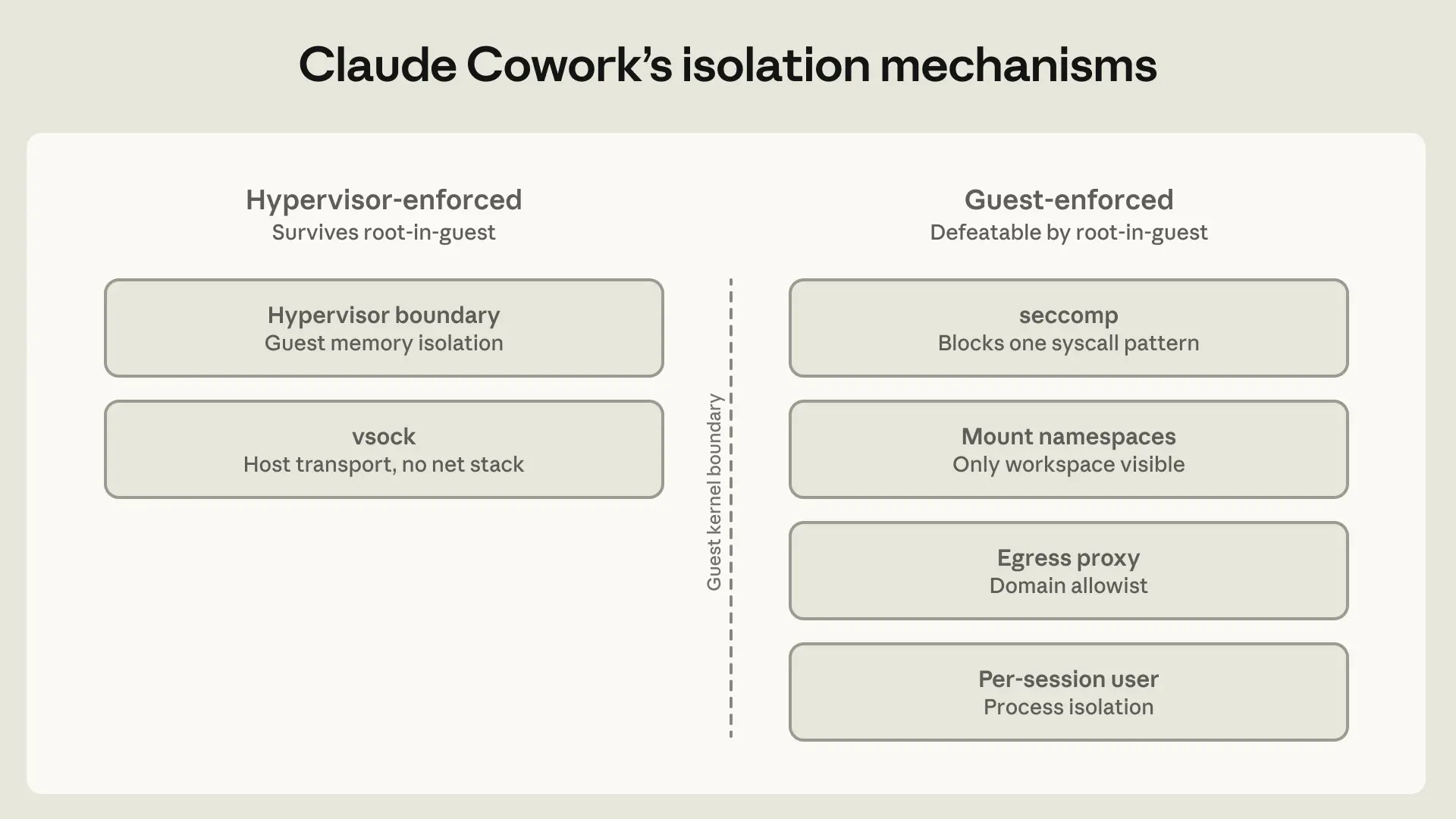
하지만 앤트로픽 팀은 전체 에이전트를 풀 VM 모드로 실행하는 것이 실질적인 문제를 일으킨다는 것을 곧 깨달았어요. VM 시작 중에 어떤 오류라도 발생하면 Cowork를 사용할 수 없게 되었거든요. 에이전트 루프를 VM 외부로 옮기되 코드 실행은 VM 내부에 유지함으로써, 클로드는 여전히 사용자에게 응답하고 오류 시 고장을 해결하는 데 도움을 줄 수 있었고, 멈추지 않게 되었어요. 이 변경은 VM이 에이전트에 의해 실행되는 코드에 대해 파일 시스템 및 네트워크 제어를 계속 강제하기 때문에 보안에 미치는 영향은 최소화되었어요.
별도로, 앤트로픽 팀은 로컬 MCP 서버도 VM 외부로 옮겼어요. VM 내부에서 실행하면 감사하기 더 어려워지고, VM 업데이트 시 취약한 종속성 문제를 일으켰으며, 데이터베이스와 같은 로컬 프로세스와의 상호 작용이 필요한 MCP를 지원하지 못했거든요. 그런 서버들은 어차피 호스트에서 실행되어야 했어요. 이 변경으로 Claude Cowork는 Claude Desktop에서 로컬 MCP 서버가 이미 작동하는 방식과 일치하게 되었는데요, 즉 MCP 서버를 사용자가 설치할 수 있는 모든 소프트웨어처럼 취급하고, 관리자가 어떤 로컬 MCP를 활성화할지(있다면) 결정하도록 위임한 거죠. 원격 MCP 서버는 사용자 머신에서 실행되지 않으므로 영향을 받지 않아요.
파일 시스템 제어는 또 다른 중요한 아키텍처 선택 사항이었어요. 클로드가 유용하려면 호스트의 일부 파일에 접근할 수 있어야 하지만, 피해 범위를 최소화하고 로컬 파일 접근에 대한 사용자에게 투명성을 제공하고 싶었거든요. 앤트로픽 팀은 다양한 파일 마운트 모드를 제공하는 것이 위험을 세분화하여 제어하는 데 도움이 된다는 것을 발견했어요. Claude Cowork는 읽기 전용, 읽기-쓰기, 읽기-쓰기-삭제 불가 모드를 제공해요. 여기서 잠재적인 주의 사항은 심볼릭 링크(symlink) 해결이 경로 유효성 검사 전에 이루어져야 한다는 거예요. 그렇지 않으면, 승인된 폴더 내의 심볼릭 링크가 외부를 가리켜 탈출할 수 있거든요. 엔터프라이즈 고객의 경우, 관리자가 MDM 설정의 마운트 경로 허용 목록을 통해 이를 제어할 수 있도록 했어요.
승인된 도메인을 통한 데이터 유출의 명확한 사례는 타사 공개를 통해 밝혀졌어요. Claude Cowork의 송신 허용 목록(egress allowlist)은 api.anthropic.com으로의 트래픽을 올바르게 통과시켰어요. 제품은 앤트로픽 팀의 API를 호출하지 않고는 작동할 수 없었거든요. 이 사례에서는 사용자가 마운트한 작업 공간에 배치된 악성 파일이 공격자가 제어하는 API 키와 함께 숨겨진 지시 사항을 담고 있었어요. 클로드는 이 지시 사항을 따라 작업 공간의 다른 파일을 읽고 공격자의 키를 사용하여 앤트로픽의 Files API를 호출했어요. 송신 프록시는 목적지를 확인하고 api.anthropic.com임을 확인한 뒤 통과시켰죠. 파일들은 공격자의 앤트로픽 계정에 업로드되었어요. 샌드박스는 완벽하게 작동했지만, 데이터는 유출된 거죠.
이전에는 앤트로픽 팀은 허용 목록을 목적지 필터, 즉 클로드에게 이 도메인들과는 대화해도 괜찮아라고 알려주는 것으로 개념화했어요. 하지만 이것은 기능 부여(capability grant)로 개념화하는 것이 더 적절할 수 있어요. 허용 목록의 어떤 도메인을 통해서든 도달할 수 있는 모든 기능이 이제 공격 표면이 되는 거죠. api.anthropic.com을 허용하는 것은 임의의 앤트로픽 계정으로 파일을 업로드하는 것을 허용한다는 의미였어요.
앤트로픽 팀은 이 문제를 해결하기 위해 VM 내부에 방어적인 중간자(man-in-the-middle) 프록시를 사용했어요. 이 프록시는 앤트로픽 팀의 API로 가는 트래픽을 가로채요. VM 자체에 프로비저닝된 세션 토큰을 포함한 요청만 통과시키고, 공격자가 삽입한 키는 프록시에서 거부하죠. 또한 서버 측 페치(fetch)를 가능하게 하는 헤더도 차단해요. 이 프록시는 VM 내부에 있는데, 그 이유는 서버 입장에서는 Cowork 요청이 다른 API 클라이언트와 구별되지 않기 때문에 VM만이 출처를 알 수 있기 때문이에요.
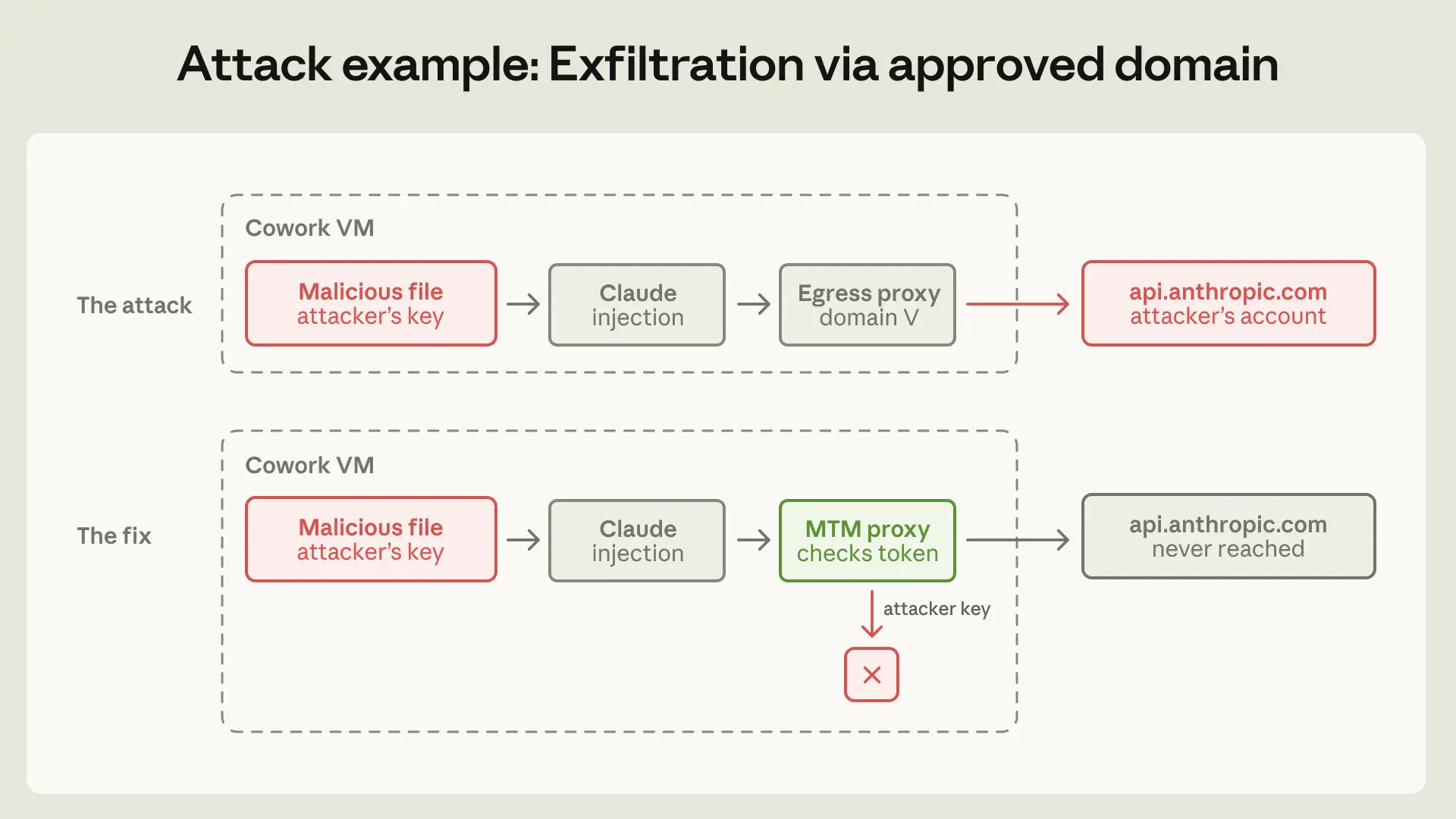
이것은 또한 '스스로 구축한 소프트웨어가 종종 가장 약하다'는 원칙의 두 번째 사례이기도 해요. 앤트로픽 팀의 제품 전반에 걸쳐 하이퍼바이저, seccomp, gVisor는 믿을 수 있었어요. 앤트로픽 팀의 커스텀 허용 목록 프록시가 바로 실패한 부분이었죠.
Claude Cowork를 평가할 때, 기업 보안 팀들은 "우리 EDR은 왜 내부를 볼 수 없나요?"라고 질문했어요. 답은 클로드를 격리하는 것과 동일한 격리 기술이 호스트 기반 엔드포인트 탐지 및 대응(EDR)도 차단한다는 것이었어요. EDR 관점에서 Claude Cowork는 불투명한 하이퍼바이저 프로세스일 뿐이에요. 게스트 내부를 검사할 수 없거든요.
격리는 가시성을 감소시키고, 불투명성은 엔드포인트 가시성에 규정 준수 태세가 의존하는 팀에게 문제가 돼요. 앤트로픽 팀의 현재 완화책은 관리자가 사후에 이벤트 로그를 검색할 수 있도록 풀 기반 OTLP 내보내기를 사용하는 것이지만, 이는 실시간 모니터링과는 달라요. 유사한 것을 구축하고 있다면, 이 대화에 일찍 예산을 편성해야 해요.
| 환경 | 임시 컨테이너 ( |
|---|
기업들은 종종 앤트로픽 팀에게 MCP 연결을 어떻게 보호하는지 물어봐요. 좋은 질문이지만, 올바른 질문은 MCP만을 넘어 더 광범위해요. 에이전트에 제공되는 모든 외부 리소스는 두 가지 위험을 동시에 나타내요. 전통적인 공급망 관점에서의 코드 실행 위험과 프롬프트 인젝션 벡터이죠. 전통적인 종속성 감사(버전 고정, 서명 확인, 소스 검토)는 첫 번째 위험을 다루지만, 두 번째 위험은 놓치게 돼요.
원격과 로컬의 차이는 생각보다 중요해요: 로컬에 설치된 도구는 감사 가능해요. 코드를 읽고, 버전을 고정하고, 도중에 변경되지 않는다는 것을 알 수 있죠. 원격 도구(호스팅된 MCP 서버, 클라우드 커넥터)는 승인한 후 언제든지 동작이 변경될 수 있어요. 설치 시점의 신뢰 결정이 더 이상 적용되지 않을 수 있는 거죠. 앤트로픽 팀의 커넥터 디렉토리는 지속적인 검토를 통해 이 문제를 해결하지만, 그 외의 모든 것은 신뢰할 수 없는 것으로 취급해야 해요. 악의적인 도구의 피해 범위가 제한된 환경에서 가짜 데이터로 먼저 실행해 보세요.
도구가 신뢰할 수 있어도 도구 출력은 공격 표면이에요: 앞서 언급된 GitHub README 예시가 바로 이 경우예요. 웹 페이지에 적용되는 모든 입력 스캐닝은 네트워크가 활성화된 도구 결과에도 동일한 엄격함으로 적용되어야 해요. 이것이 레이턴시를 추가하고 완벽한 방어책은 아닐지라도, 앤트로픽 팀은 실시간 검사를 지향해요. 오염된 도구 반환 값이 에이전트를 데이터 유출로 유도한 후에는, 로그에는 성공적이고 승인된 API 호출로만 나타나거든요. 사후에 찾아낼 수 있는 신호가 없어요.
Claude Code와 Claude Cowork에서 도구 호출은 네트워크 및 파일 정책을 강제하고 모델의 컨텍스트에 들어가기 전에 반환 값을 검사할 수 있는 프록시를 통해 라우팅돼요. 이 검사를 수행하는 분류기는 작고 빠른 모델일 수 있어요. 추론을 수행하는 모델일 필요는 없거든요.
모델과 제품은 빠르게 발전하고 있어요. 그에 따라 위험도 변형되고 진화하며, 앤트로픽 팀의 완화책도 이에 발맞춰야 해요.
**영구 메모리 오염: **세션 간에 지속되는 에이전트 컨텍스트의 비중이 계속 늘어나고 있어요. 여기에는 제품 메모리, CLAUDE.md 파일, 마운트된 작업 공간, 예약되거나 장기 실행되는 에이전트의 상태 디렉터리가 포함되죠. 이런 곳에 침투한 인젝션은 에이전트가 시작될 때마다 다시 로드돼요. 더 많은 에이전트 상태가 세션을 넘어서도 유지될수록, 고전적인 '사후 공격(post-exploitation)' 관점에서 새로운 영속성 메커니즘으로 인해 위협을 받게 돼요. 세션 시작 시 좋은 분류기가 더욱 보편화될 필요가 있어요.
멀티 에이전트 신뢰 에스컬레이션: 한편으로는 하위 에이전트가 신뢰할 수 없는 콘텐츠를 격리하여, 원시 텍스트 대신 구조화된 사실을 주 에이전트에게 반환할 수 있어요. 다른 한편으로는 이것이 악용될 수 있는데요, 하위 에이전트의 출력이 원시 도구 결과보다 더 높은 신뢰 수준으로 취급된다면, 즉 그 출력이 "앤트로픽 팀"으로부터 왔다고 여겨진다면, 새로운 프롬프트 인젝션 벡터가 도입되는 거죠. 멀티 에이전트 시스템에서는 서로 다른 신뢰 수준을 할당하는 것과 신뢰 에스컬레이션에 취약해지는 것 사이에 상충 관계가 있어요.
에이전트 식별: Claude Cowork가 에이전트 식별에 대해 내놓은 답은 구체적이에요. 자격 증명은 호스트 키체인에 남아있고, VM은 세션별로 범위가 제한된 토큰을 받으며, 이 토큰은 사용자의 토큰과 독립적으로 취소될 수 있어요. 하지만 앤트로픽 팀은 더 광범위한 교차 플랫폼 에이전트 식별 문제와 씨름하기 시작했어요. 에이전트가 자체적인 주요 식별자(principal identity)를 가져야 할까요, 아니면 사용자의 확장으로 행동하며 사용자의 권한을 상속받아야 할까요? 궁극적으로 답은 두 가지가 혼합된 형태일 수 있어요.
에이전트가 더욱 유능해짐에 따라, 공격 표면은 끊임없이 변화하고 있어요. 앤트로픽 팀이 목격한 유형의 실패는 업계와 연구실 전반에 걸쳐 반복될 가능성이 높아요. 공유된 벤치마크와 공개 규범부터 공통 식별 표준, 그리고 여러 공급업체 간의 레드팀 훈련에 이르기까지 에이전트별 보안 태세에 대한 집단적인 투자가 필요해요. 이 글에서는 격리에 초점을 맞췄지만, 이는 에이전트 보안 전체 그림의 한 부분일 뿐이에요. 거버넌스, 관찰 가능성 및 나머지 스택에 대해서는 NIST의 AI 에이전트 식별 및 인증 프로젝트, 호주 ACSC가 CISA 및 영국 NCSC와 함께 주도한 에이전트 AI 도입에 대한 6개 기관 지침, 그리고 AI 관리 표준인 ISO/IEC 42001을 참고해 보세요. 앤트로픽 팀의 Glasswing 이니셔티브도 하나의 기여이지만, 이 중요한 문제에 대해 파트너 및 경쟁사와 협력하기를 기대하고 있어요.
요약하자면, 앤트로픽 팀이 계속해서 돌아보는 몇 가지 원칙들이 있어요.
환경 계층에서 먼저 격리를 설계하고, 그 다음 모델 계층에서 행동을 유도하세요. 앤트로픽 팀에게 가장 많은 것을 가르쳐 준 두 가지 사고, 즉 직원 피싱과 타사 허용 목록 공개는 모두 데이터가 허용된 경로를 통해 외부로 나간 송신(egress) 사례였어요. 각 경우에 모델 계층은 아무런 도움을 줄 수 없었죠. 모델이 포착할 만한 비정상적인 것이 없었거든요. 확률적인 모든 것이 실패할 때, 결정론적인 경계가 방어막이 되어 주는 거예요.
격리 강도를 사용자의 감독 능력에 맞추세요. Bash를 읽을 수 있는 개발자와 그렇지 않은 지식 근로자는 동일한 위협 모델을 가지고 있지 않아요. 사용자가 에이전트가 하려는 일을 평가할 수 있는지 여부가 격리 전략을 결정하는 데 도움이 되어야 하고, 양방향으로 잘못된 답변(전문가에게 너무 많은 마찰, 비전문가에게 너무 많은 신뢰)을 내리는 것 자체가 실패예요.
커스텀 컴포넌트는 조심하세요. 수많은 공격자들의 관심을 견뎌온 검증된 하이퍼바이저, 시스템 호출 필터, 컨테이너 런타임은 앤트로픽 팀이 만들 어떤 것보다도 더 오래 살아남았어요. 여기에 설명된 모든 배포에서 표준 기본 요소들은 잘 버텨주었지만, 그것들 주변에 앤트로픽 팀이 만든 부분들이 결함을 노출시켰죠.
궁극적으로 에이전트가 새로운 소프트웨어 범주일 수 있지만, 그들의 시스템 수준 상호 작용은 그렇지 않아요. 여전히 파일을 읽고, 소켓을 열고, 프로세스를 생성하죠. 이것이 바로 성숙한 도구를 이용한 격리가 결정적으로 실행 가능한 방어책이 되는 이유예요. AI가 발전함에 따라 배포의 위험-보상 균형은 계속해서 변화하겠지만, 피해 범위에 대한 엄격한 한계를 설정하는 것은 종종 그 균형을 올바른 방향으로 이끌어줘요.
작성자: Max McGuinness, Mikaela Grace, Jiri De Jonghe, Jake Eaton, Abel Ribbink.
또한 Hanah Ho, Hasnain Lakhani, Pedram Navid, Molly Villagra, Maya Nielan, Akila Srinivasan, Sam Attard, Alfred Xing, Mohamad El Hajj, Gabby Curtis, David Dworken, Adam Jones, Amie Rotherham, Christian Ryan, Lucas Smedley, Brett Andrews 및 기타 기여자들에게 감사드립니다.
앤트로픽의 보안 및 제품 엔지니어링 팀, 그리고 Claude 제품의 취약점을 보고해 주신 개인 및 기관들에게 특별한 감사를 전합니다.
제품 업데이트, 사용 방법, 커뮤니티 스포트라이트 등 다양한 소식을 매달 이메일로 보내드려요.