Claude Opus 4.7 출시 소식!
요약
저희의 최신 모델 Claude Opus 4.7이 정식 출시되었어요! 소프트웨어 엔지니어링, 고해상도 이미지 이해, 지시사항 준수 능력이 대폭 향상되어 복잡한 작업을 더 똑똑하고 효율적으로 처리하고, 더 안정적인 에이전트 워크플로우를 구현할 수 있게 됐어요.
인사이트
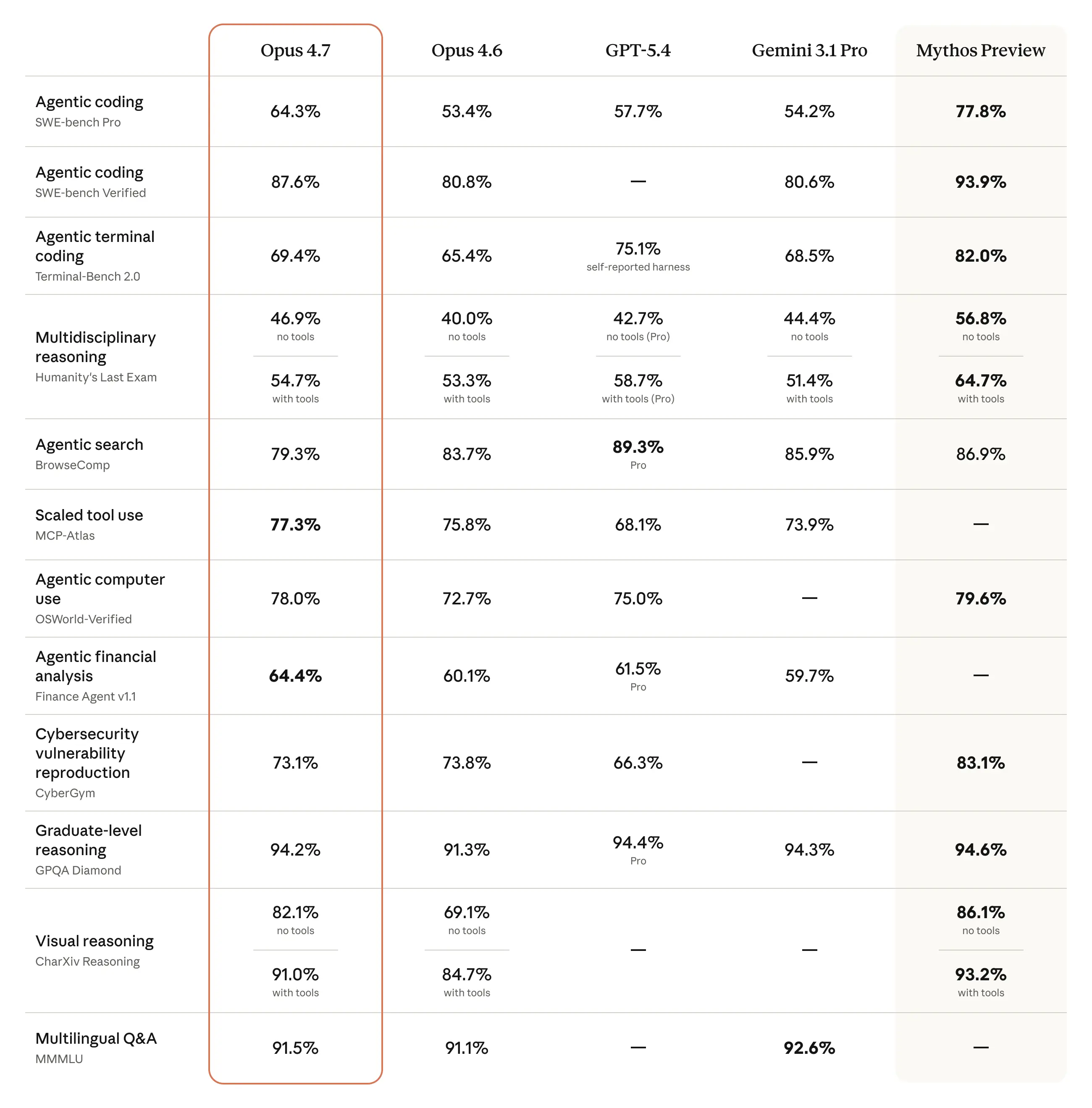
- **고급 소프트웨어 엔지니어링 능력 대폭 향상:** 가장 까다로운 코딩 작업도 엄격하고 일관되게 처리하며, 심지어 스스로 결과를 검증하는 능력까지 갖춰 개발자들에게 큰 도움이 될 거예요.
- **고해상도 멀티모달 지원 및 정확한 지시사항 준수:** 이전보다 3배 이상 높은 해상도의 이미지를 인식하고, 지시사항을 훨씬 더 문자 그대로 정확하게 따르게 되어 복잡한 시각 정보 처리나 섬세한 작업에 최적화되었어요.
- **안전성 및 유연한 제어 기능 강화:** 사이버 보안 관련 사용에 대한 안전장치가 추가되었고, 새로운 'xhigh' 노력 수준과 '태스크 예산' 기능으로 사용자가 추론 복잡성과 비용 간의 균형을 더 세밀하게 조절할 수 있게 되었어요.
왜 중요한가
Claude Opus 4.7은 개발자들이 이전에는 직접 관리해야 했던 복잡하고 장기적인 코딩 및 에이전트 작업을 AI에게 더 자신 있게 맡길 수 있도록 만들어요. 이는 개발 생산성을 크게 끌어올리고, AI가 단순히 보조하는 것을 넘어 실제 팀원처럼 자율적으로 문제를 해결하며 개발 워크플로우를 혁신할 수 있는 가능성을 열어준다는 점에서 아주 중요해요.
Claude Opus 4.7 출시 소식!

저희의 최신 모델인 Claude Opus 4.7이 드디어 정식으로 출시되었어요.
Opus 4.7은 특히 가장 어려운 작업들에서 뛰어난 향상을 보여주며, 고급 소프트웨어 엔지니어링 분야에서 Opus 4.6보다 눈에 띄게 개선되었어요. 사용자들은 예전에는 세심한 감독이 필요했던 가장 까다로운 코딩 작업을 Opus 4.7에게 안심하고 맡길 수 있다고 해요. Opus 4.7은 복잡하고 오래 걸리는 작업을 엄격하고 일관성 있게 처리하고, 지시사항에 매우 정확하게 주의를 기울이며, 결과를 보고하기 전에 스스로 출력을 검증하는 방법까지 고안해낸다고 하네요.
이 모델은 시각 능력도 훨씬 좋아졌어요. 더 높은 해상도로 이미지를 볼 수 있게 되었죠. 전문적인 작업을 할 때는 더 세련되고 창의적인 결과물을 내놓아서, 더 고품질의 인터페이스, 슬라이드, 문서 등을 만들어내요. 그리고 가장 강력한 모델인 Claude Mythos Preview보다는 광범위한 능력을 갖추진 못했지만, Opus 4.6에 비해서는 다양한 벤치마크에서 더 좋은 결과를 보여주고 있어요.
지난주 저희는 AI 모델의 사이버 보안 위험과 이점 모두를 강조하는 Project Glasswing을 발표했어요. 그때 Claude Mythos Preview의 출시를 제한하고, 덜 강력한 모델에서 먼저 새로운 사이버 보안 장치를 테스트할 것이라고 말씀드렸죠. Opus 4.7이 바로 그런 첫 번째 모델이에요. 사이버 보안 기능은 Mythos Preview만큼 고급스럽지는 않아요(사실, 훈련 과정에서 이 기능을 차등적으로 줄이려는 실험도 했어요). 저희는 Opus 4.7을 출시하면서 금지되거나 고위험 사이버 보안 사용을 나타내는 요청을 자동으로 감지하고 차단하는 안전장치를 함께 제공하고 있어요. 이 안전장치들이 실제 환경에서 어떻게 작동하는지를 통해 배우는 것은 궁극적으로 Mythos급 모델의 광범위한 출시라는 목표를 향해 나아가는 데 큰 도움이 될 거예요.
Opus 4.7을 합법적인 사이버 보안 목적(예: 취약점 연구, 침투 테스트, 레드팀 활동)으로 사용하고 싶으신 보안 전문가분들은 저희의 새로운 사이버 검증 프로그램(Cyber Verification Program)에 참여해 주세요.
Opus 4.7은 오늘부터 모든 Claude 제품과 저희 API, Amazon Bedrock, Google Cloud의 Vertex AI, Microsoft Foundry에서 사용 가능해요. 가격은 Opus 4.6과 동일하게 입력 토큰 100만 개당 5달러, 출력 토큰 100만 개당 25달러로 유지돼요. 개발자분들은 Claude API를 통해 claude-opus-4-7을 사용할 수 있어요.
Claude Opus 4.7 테스트 결과
Claude Opus 4.7은 얼리 액세스 테스터들로부터 아주 좋은 피드백을 받았어요.
1
초기 테스트에서 Claude Opus 4.7은 개발자들에게 상당한 도약의 잠재력을 보여주고 있어요. 이전 Claude 모델들을 훨씬 뛰어넘어 계획 단계에서 스스로 논리적 오류를 잡아내고 실행을 가속화하죠. 수백만 명의 소비자와 기업에 금융 기술 플랫폼을 제공하는 입장에서, 이 속도와 정확성의 조합은 판도를 바꿀 수 있을 거예요. 고객들이 매일 의존하는 신뢰할 수 있는 금융 솔루션을 더 빠르게 제공하기 위한 개발 속도를 가속화할 수 있겠네요.
2
Anthropic은 이미 코딩 모델의 표준을 세웠는데, Claude Opus 4.7은 시장에서 최고 수준의 모델로서 그 기준을 더욱 의미 있게 끌어올리고 있어요. 저희 내부 평가에서 이 모델은 순수한 능력뿐만 아니라 실제 비동기 워크플로우(자동화, CI/CD, 장기 실행 작업)를 얼마나 잘 처리하는지에서도 돋보였죠. 또한, 사용자에게 단순히 동의하는 대신 문제에 대해 더 깊이 생각하고 더 주관적인 관점을 제시해요.
3
Claude Opus 4.7은 Hex가 평가한 모델 중 가장 강력한 모델이에요. 그럴듯하지만 잘못된 대체 답변을 제공하는 대신, 데이터가 누락되었을 때 정확히 보고하고, Opus 4.6조차 빠지는 불일치 데이터 함정에도 넘어가지 않아요. 더 똑똑하고 효율적인 Opus 4.6인 셈이죠. 적은 노력으로 Opus 4.7을 사용하는 것이 중간 노력으로 Opus 4.6을 사용하는 것과 거의 비슷해요.
4
저희의 93가지 코딩 벤치마크에서 Claude Opus 4.7은 Opus 4.6보다 해결 능력을 13% 향상시켰어요. 여기에는 Opus 4.6과 Sonnet 4.6 모두 풀지 못했던 4가지 작업도 포함되어 있죠. 더 빠른 중간 레이턴시(latency)와 엄격한 지시사항 준수 능력까지 더해져 복잡하고 오래 걸리는 코딩 워크플로우에 특히 의미가 있어요. 이러한 다단계 작업의 마찰을 줄여 개발자들이 흐름을 유지하고 빌드에 집중할 수 있도록 도와요.
5
저희 내부 연구 에이전트 벤치마크에 따르면, Claude Opus 4.7은 다단계 작업에서 저희가 본 가장 강력한 효율성 기준을 가지고 있어요. 저희 6개 모듈 전체에서 0.715점으로 최고 점수를 기록했고, 테스트한 어떤 모델보다 가장 일관된 긴 컨텍스트 성능을 보여주었죠. 가장 큰 모듈인 일반 금융(General Finance)에서는 Opus 4.6의 0.767점보다 의미 있게 향상된 0.813점을 기록했고, 그룹 내에서 최고의 공개 및 데이터 규율도 보여주었어요. 그리고 Opus 4.6이 고전했던 연역 논리(deductive logic) 분야에서도 Opus 4.7은 탄탄한 성능을 자랑해요.
6
Claude Opus 4.7은 모델이 작업을 조사하고 완료하는 데 할 수 있는 것의 한계를 확장하고 있어요. Anthropic은 장기 실행 시 지속적인 추론을 위해 분명히 최적화했으며, 이는 시장을 선도하는 성능으로 나타나고 있죠. 엔지니어들이 에이전트와 1:1로 작업하는 방식에서 병렬로 에이전트를 관리하는 방식으로 전환함에 따라, 이는 새로운 워크플로우를 가능하게 하는 바로 그런 최전선 능력이에요.
7
Claude Opus 4.7의 멀티모달 이해력에서 큰 개선을 보고 있어요. 화학 구조를 읽는 것부터 복잡한 기술 다이어그램을 해석하는 것까지 말이죠. 더 높은 해상도 지원은 Solve Intelligence가 생명 과학 특허 워크플로우를 위한 최고의 도구를 구축하는 데 도움을 주고 있어요. 초안 작성 및 심사부터 침해 감지 및 무효화 차트 작성까지 모든 과정에서요.
8
Claude Opus 4.7은 Devin에서 장기 자율성(long-horizon autonomy)을 새로운 수준으로 끌어올려요. 몇 시간 동안 일관성 있게 작동하고, 포기하지 않고 어려운 문제를 해결하며, 이전에는 안정적으로 실행할 수 없었던 심층 조사 작업을 가능하게 하죠.
9
Replit에게 Claude Opus 4.7은 쉬운 업그레이드 결정이었어요. 저희 사용자분들이 매일 하는 작업에서 더 낮은 비용으로 동일한 품질을 달성하는 것을 확인했죠. 로그 및 추적 분석, 버그 찾기, 수정 제안과 같은 작업에서 더 효율적이고 정확했어요. 개인적으로는 기술 토론 중에 제가 더 나은 결정을 내리도록 도와주기 위해 반박하는 점이 마음에 들어요. 정말 더 좋은 동료 같다는 느낌이 드네요.
0
Claude Opus 4.7은 Harvey의 BigLaw Bench에서 90.9%의 높은 정확도를 보여주며 강력한 실질적 정확성을 입증했어요. 검토 테이블에서 더 나은 추론 보정 능력과 모호한 문서 편집 작업을 훨씬 더 똑똑하게 처리하는 모습을 보여주었죠. 역사적으로 선도적인 모델들도 어려워했던, 양도 조항과 지배권 변경 조항을 정확하게 구분해요. 저희 평가 전반에서 내용은 항상 강점으로 평가되었어요. 정확하고, 철저하며, 잘 인용되었죠.
1
Claude Opus 4.7은 자율성과 더 창의적인 추론 능력 면에서 매우 인상적인 코딩 모델이에요. CursorBench에서 Opus 4.7은 Opus 4.6의 58% 대비 70%를 넘어서며 능력 면에서 의미 있는 도약을 보여주었어요.
복잡한 다단계 워크플로우에서 Claude Opus 4.7은 확실한 개선을 보여주었어요. Opus 4.6보다 토큰은 덜 사용하면서도 도구 오류는 1/3로 줄였고, 성능은 14%나 향상되었죠. 저희의 암묵적 필요성 테스트를 통과한 첫 번째 모델이며, 이전 Opus 모델들을 멈추게 했던 도구 오류에도 불구하고 계속 실행돼요. 이 정도의 안정성 향상 덕분에 Notion Agent가 진정한 팀원처럼 느껴져요.
2
저희 평가에서 핵심 오케스트레이터 에이전트의 도구 호출 및 계획 정확도에서 두 자릿수 향상을 확인했어요. 사용자들이 Hebbia를 활용하여 검색, 슬라이드 생성 또는 문서 생성과 같은 사용 사례를 계획하고 실행함에 따라, Claude Opus 4.7은 이러한 워크플로우에서 에이전트의 의사 결정 능력을 향상시킬 잠재력을 보여주고 있어요.
3
Rakuten-SWE-Bench에서 Claude Opus 4.7은 Opus 4.6보다 3배 더 많은 프로덕션 작업을 해결했고, 코드 품질 및 테스트 품질에서 두 자릿수 향상을 보였어요. 이는 의미 있는 개선이자 저희 팀이 매일 수행하는 엔지니어링 작업에 대한 확실한 업그레이드예요.
4
CodeRabbit의 코드 검토 작업량에 있어 Claude Opus 4.7은 저희가 테스트한 모델 중 가장 뛰어난 모델이에요. 가장 복잡한 PR에서 탐지하기 가장 어려운 버그들을 찾아내며 리콜(Recall)이 10% 이상 향상되었고, 커버리지 증가에도 불구하고 정밀도(Precision)는 안정적으로 유지되었죠. 저희 하네스에서는 GPT-5.4 xhigh보다 약간 더 빠르며, 출시와 함께 가장 중요한 검토 작업에 투입할 예정이에요.
5
Genspark의 Super Agent를 위해 Claude Opus 4.7은 가장 중요한 세 가지 생산 차별화 요소를 완벽하게 충족했어요. 바로 루프 저항성(loop resistance), 일관성, 그리고 우아한 오류 복구 능력이죠. 루프 저항성이 가장 중요해요. 18개의 쿼리 중 1개에서 무한 루프에 빠지는 모델은 컴퓨팅 자원을 낭비하고 사용자를 막아버리니까요. 낮은 분산은 프로덕션 환경에서 예측 불가능한 상황이 적다는 것을 의미하고요. 그리고 Opus 4.7은 저희가 측정한 가장 높은 '호출당 품질 비율'을 달성했어요.
6
Claude Opus 4.7은 Warp에게 의미 있는 도약이에요. Opus 4.6도 개발자들을 위한 최고의 모델 중 하나인데, 이 모델은 그 위에 측정 가능할 정도로 더 철저해졌죠. 이전 Claude 모델들이 실패했던 Terminal Bench 작업을 통과했고, Opus 4.6이 해결하지 못했던 까다로운 동시성 버그도 해결했어요. 저희에게는 이것이 바로 신호예요.
7
Claude Opus 4.7은 대시보드와 데이터가 풍부한 인터페이스를 구축하는 데 있어 세계 최고의 모델이에요. 디자인 감각은 정말 놀라울 정도죠. 제가 실제로 출시할 만한 선택들을 해요. 이제 저의 기본 일상 업무 드라이버가 되었어요.
8
Claude Opus 4.7은 Quantium에서 테스트한 모델 중 가장 유능한 모델이에요. 독점적인 벤치마킹 솔루션을 통해 선도적인 AI 모델들과 비교했을 때, 가장 큰 개선점은 가장 중요한 부분에서 나타났어요. 바로 추론의 깊이, 구조화된 문제 정의, 그리고 복잡한 기술 작업이죠. 수정 사항이 줄어들고, 반복 작업이 빨라졌으며, 고객이 가져오는 가장 어려운 문제들을 해결하기 위한 더 강력한 결과물을 얻게 되었어요.
9
Claude Opus 4.7은 지능 면에서 정말 한 단계 발전한 느낌이에요. 코드 품질이 눈에 띄게 향상되었고, 예전에 쌓이던 의미 없는 래퍼 함수와 폴백 스캐폴딩을 제거하며, 스스로 코드를 수정해 나가는군요. Sonnet 3.7에서 Claude 4 시리즈로 넘어왔을 때 이후로 우리가 본 가장 깔끔한 도약이에요.
0
XBOW의 자율 침투 테스트의 핵심인 '컴퓨터 사용' 작업에서, 새로운 Claude Opus 4.7은 한 단계 발전했어요. 저희의 시각 정확도 벤치마크에서 Opus 4.6의 54.5% 대비 98.5%를 기록했죠. Opus에서 가장 큰 골칫거리였던 점이 효과적으로 사라졌고, 이는 이전에는 사용할 수 없었던 모든 종류의 작업에 Opus를 활용할 수 있게 해줘요.
1
Claude Opus 4.7은 Vercel에게 퇴보 없이 확실한 업그레이드예요. 원샷 코딩 작업에서 경이로운 성능을 보여주며, Opus 4.6보다 더 정확하고 완전하며, 자신의 한계에 대해 훨씬 더 솔직하죠. 심지어 작업을 시작하기 전에 시스템 코드에 대한 증명(proof)까지 수행하는데, 이는 이전 Claude 모델에서는 볼 수 없었던 새로운 행동이에요.
2
Claude Opus 4.7은 매우 강력하며, Factory Droids의 작업 성공률을 Opus 4.6보다 10%에서 15%까지 끌어올렸어요. 도구 오류는 줄고, 검증 단계에서 더 안정적으로 후속 작업을 수행하죠. 작업을 중간에 멈추지 않고 끝까지 완료하는데, 이는 엔터프라이즈 엔지니어링 팀이 정확히 필요로 하는 부분이에요.
3
Claude Opus 4.7은 완전한 Rust 텍스트-음성 엔진(신경망 모델, SIMD 커널, 브라우저 데모 포함)을 자율적으로 처음부터 구축한 다음, 자체 출력을 음성 인식기에 넣어 Python 참조와 일치하는지 확인했어요. 몇 달이 걸릴 시니어 엔지니어링 작업을 자율적으로 해낸 거죠. Opus 4.6과의 차이는 분명하며, 코드베이스는 공개되어 있어요.
4
Claude Opus 4.7은 이전 Claude 모델들이 통과하지 못했던 세 가지 TBench 작업을 통과했고, 이전 최고의 모델이 놓쳤던 경합 조건(race condition)을 포함한 버그를 해결했어요. 실제 문제를 식별하는 데 있어 강력한 정확성을 보여주며, 다른 모델들이 포기했거나 해결하지 못했던 중요한 발견들을 찾아내요. Qodo의 실제 코드 검토 벤치마크에서 우리는 최고 수준의 정확도를 확인했죠.
5
Databricks의 OfficeQA Pro에서 Claude Opus 4.7은 문서 추론 능력이 훨씬 강력해졌어요. 원본 정보로 작업할 때 Opus 4.6보다 오류가 21%나 줄었죠. 저희의 데이터 기반 에이전트 추론 벤치마크 전반에서 엔터프라이즈 문서 분석을 위한 최고의 Claude 모델이에요.
6
Ramp에게 Claude Opus 4.7은 에이전트 팀 워크플로우에서 돋보여요. 특히 도구, 코드베이스, 디버깅 컨텍스트를 아우르는 엔지니어링 작업에서 역할 충실도, 지시사항 준수, 협업, 복잡한 추론 능력이 더욱 강력해진 것을 보고 있어요. Opus 4.6과 비교했을 때 단계별 안내가 훨씬 덜 필요해서, 저희 엔지니어링 팀이 운영하는 내부 에이전트 워크플로우를 확장하는 데 도움이 돼요.
7
Claude Opus 4.7은 Bolt의 장기적인 앱 빌딩 작업에서 Opus 4.6보다 측정 가능하게 더 좋았어요. 최상의 경우 최대 10%까지 향상되었고, 매우 에이전틱(agentic)한 모델에서 흔히 예상되는 퇴보도 없었죠. 사용자분들이 한 번의 세션에서 완성할 수 있는 작업의 한계를 확장하고 있어요.
아래는 Opus 4.7의 초기 테스트에서 얻은 주요 내용과 참고 사항들이에요.
- 지시사항 준수. Opus 4.7은 지시사항을 따르는 능력이 상당히 향상되었어요. 흥미롭게도, 이는 이전 모델들을 위해 작성된 프롬프트가 때로는 예상치 못한 결과를 낳을 수 있다는 의미이기도 하죠. 이전 모델들이 지시사항을 느슨하게 해석하거나 일부를 아예 건너뛰었던 것과 달리, Opus 4.7은 지시사항을 문자 그대로 받아들이거든요. 따라서 사용자분들은 프롬프트와 하네스를 그에 맞춰 다시 조정해야 할 거예요.
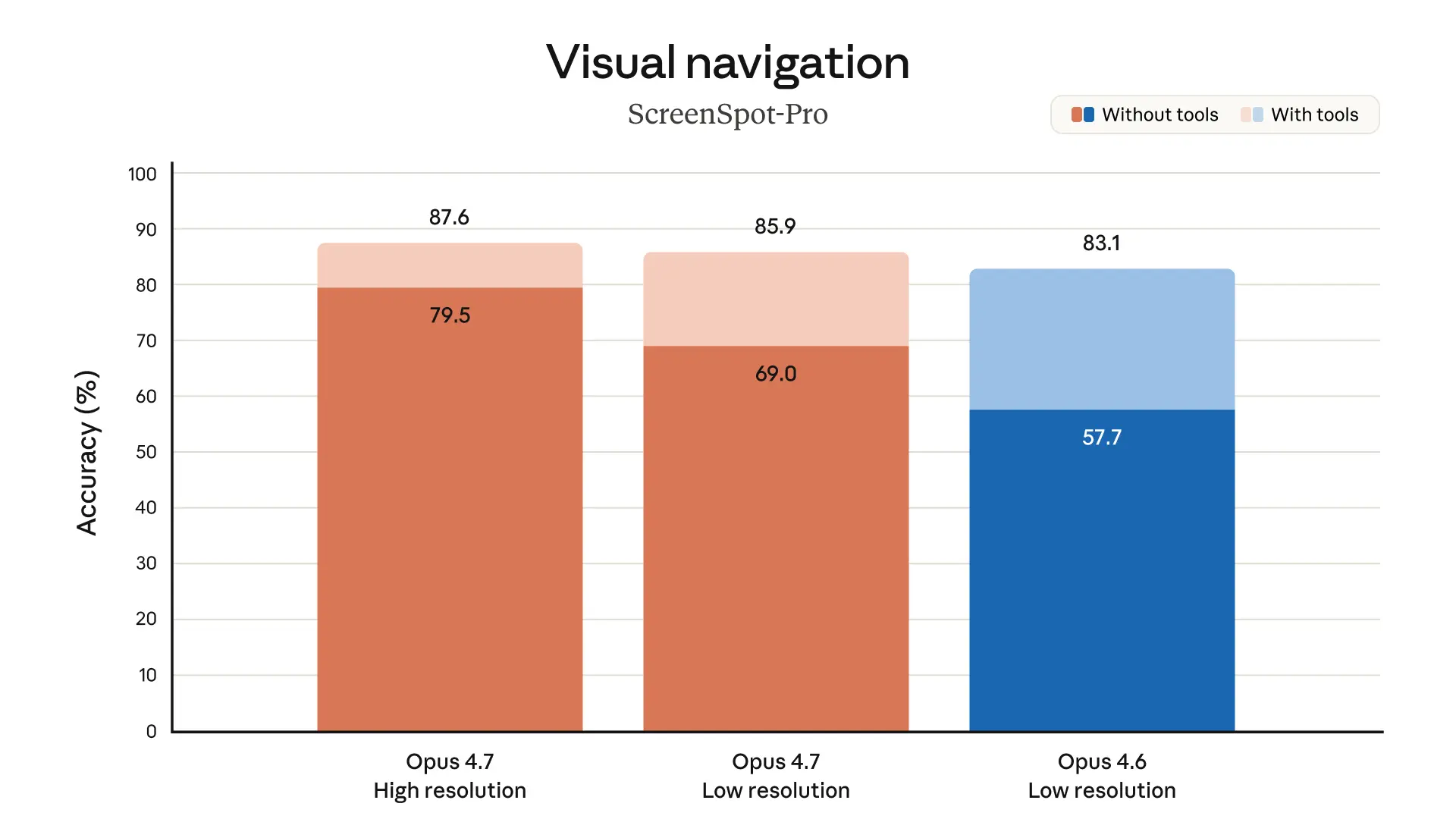
- 향상된 멀티모달 지원. Opus 4.7은 고해상도 이미지에 대한 시각 능력이 더 좋아졌어요. 긴 쪽 가장자리가 최대 2,576픽셀(약 3.75메가픽셀)에 달하는 이미지를 받아들일 수 있는데, 이는 이전 Claude 모델들보다 3배 이상 많은 픽셀이죠. 이는 섬세한 시각적 디테일에 의존하는 풍부한 멀티모달 사용 사례들을 가능하게 해요. 예를 들어, 조밀한 스크린샷을 읽는 컴퓨터 사용 에이전트, 복잡한 다이어그램에서 데이터 추출, 픽셀 단위의 정확한 참조가 필요한 작업 등이요.1
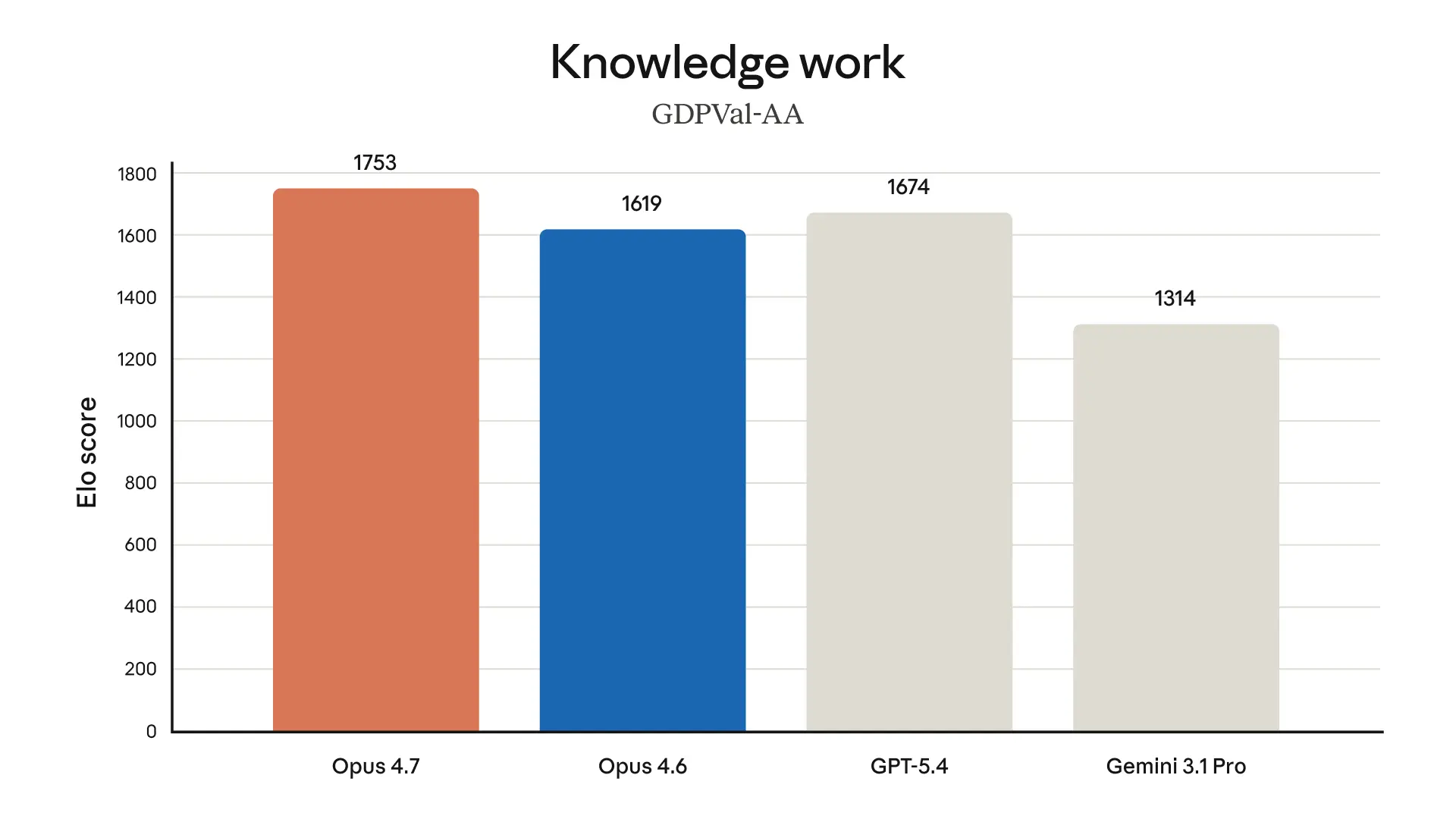
- 실제 업무. 위 표에서 보시다시피 금융 에이전트 평가에서 최고 점수를 받은 것 외에도, 저희 내부 테스트 결과 Opus 4.7은 Opus 4.6보다 더 효과적인 금융 분석가로 나타났어요. 엄격한 분석과 모델을 생성하고, 더 전문적인 프레젠테이션을 만들며, 작업 전반에 걸쳐 더 긴밀한 통합을 보여주었죠. 또한, Opus 4.7은 금융, 법률 및 기타 분야에 걸쳐 경제적으로 가치 있는 지식 작업을 평가하는 제3자 평가인 GDPval-AA에서도 최고 수준의 성능을 보였어요.
- 기억력. Opus 4.7은 파일 시스템 기반 메모리 사용을 더 잘해요. 길고 여러 세션에 걸친 작업에서 중요한 메모들을 기억하고, 이를 활용하여 새로운 작업으로 넘어가면서 필요한 사전 컨텍스트를 줄여줘요.
아래 차트들은 다양한 도메인에서 사전 출시 테스트의 더 많은 평가 결과를 보여주고 있어요.
안전성 및 정렬 (Alignment)
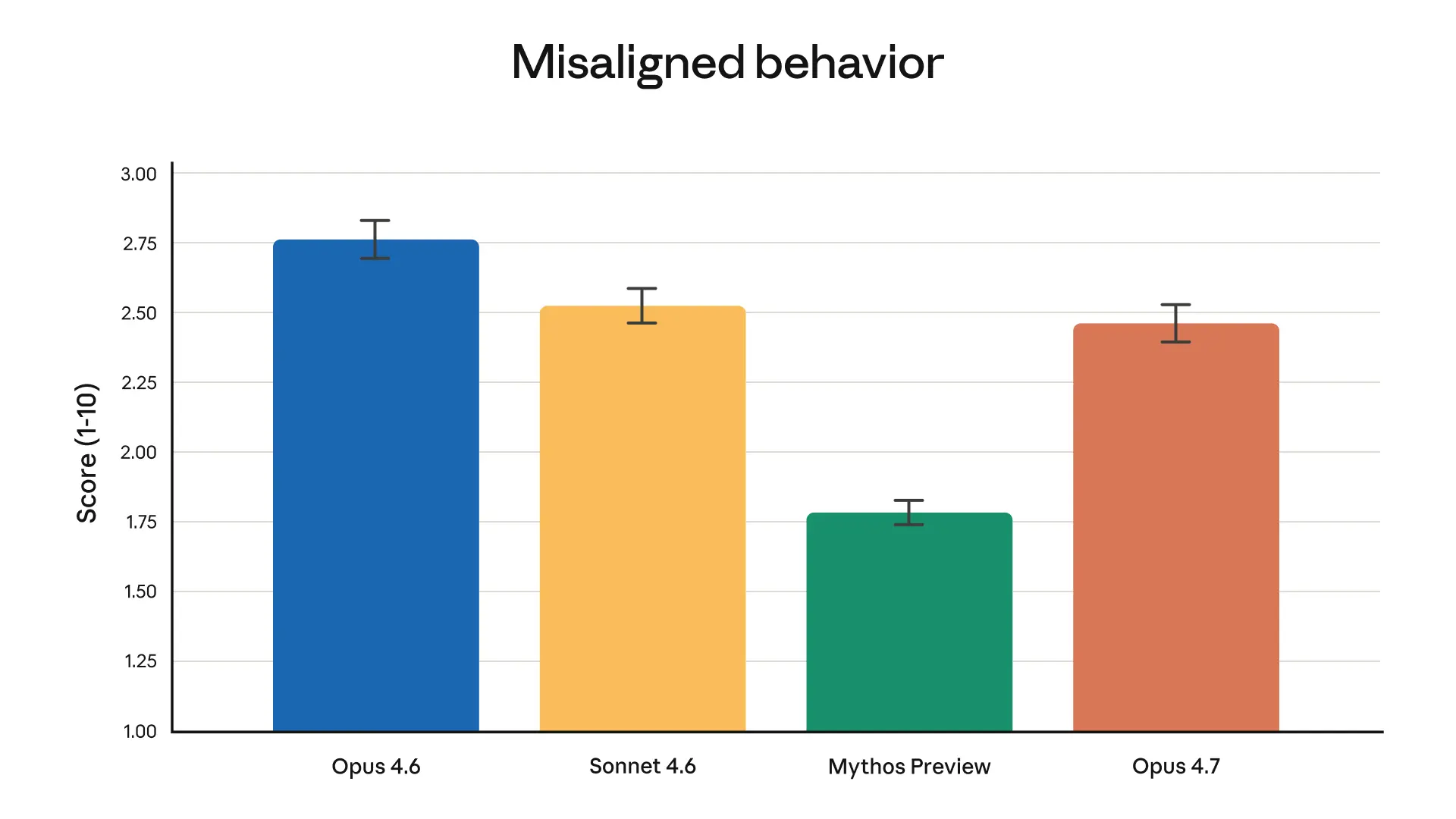
전반적으로 Opus 4.7은 Opus 4.6과 비슷한 안전성 프로필을 보여주고 있어요. 저희 평가에 따르면 기만, 아첨, 오용 협력과 같은 우려스러운 행동 발생률이 낮게 나타났죠. 정직성 및 악성 '프롬프트 주입' 공격에 대한 저항성과 같은 일부 측정에서는 Opus 4.7이 Opus 4.6보다 향상되었고요. 하지만 (통제 약물에 대해 지나치게 상세한 위해 감소 조언을 제공하는 경향과 같이) 다른 측정에서는 Opus 4.7이 약간 더 약한 모습을 보이기도 해요. 저희의 정렬 평가에서는 이 모델이 “대체로 잘 정렬되어 있고 신뢰할 수 있지만, 행동이 완전히 이상적이지는 않다”고 결론 내렸어요. Mythos Preview는 저희 평가에 따르면 여전히 저희가 훈련한 모델 중 가장 잘 정렬된 모델이라는 점을 참고해 주세요. 저희의 안전성 평가에 대한 자세한 내용은 Claude Opus 4.7 시스템 카드에서 확인할 수 있어요.
오늘 함께 출시되는 다른 업데이트들
Claude Opus 4.7 자체 외에도, 다음과 같은 업데이트들을 함께 출시하고 있어요.
- 더 세밀한 노력 제어: Opus 4.7은
high와max사이에 새로운xhigh(“추가 높은”) 노력 수준을 도입하여, 사용자들이 어려운 문제에 대한 추론과 레이턴시(latency) 사이의 균형을 더 세밀하게 제어할 수 있도록 했어요. Claude Code에서는 모든 계획에 대한 기본 노력 수준을xhigh로 상향 조정했어요. 코딩 및 에이전틱(agentic) 사용 사례를 위해 Opus 4.7을 테스트할 때는high또는xhigh노력 수준으로 시작하는 것을 추천해요. - Claude 플랫폼 (API)에서: 고해상도 이미지 지원 외에도, 저희는 공개 베타로 태스크 예산(task budgets)을 출시하고 있어요. 이는 개발자들이 Claude의 토큰 사용량을 안내하여 더 긴 실행 과정에서 작업을 우선순위화할 수 있는 방법을 제공하죠.
- Claude Code에서: 새로운
/ultrareview슬래시 명령어는 변경 사항을 꼼꼼히 검토하고 세심한 리뷰어가 찾아낼 만한 버그와 디자인 문제를 알려주는 전용 검토 세션을 생성해요. Pro 및 Max Claude Code 사용자분들께는 세 번의 무료 울트라리뷰를 제공하여 사용해 볼 수 있도록 했어요. 또한, Max 사용자에게는 자동 모드(auto mode)를 확장 적용했어요. 자동 모드는 Claude가 사용자 대신 결정을 내리는 새로운 권한 옵션으로, 권한을 모두 건너뛰는 것보다 위험 부담이 적으면서도 중단 없이 더 긴 작업을 실행할 수 있게 해줘요.
Opus 4.6에서 Opus 4.7으로 마이그레이션하기
Opus 4.7은 Opus 4.6의 직접적인 업그레이드 모델이지만, 토큰 사용량에 영향을 미치는 두 가지 변경 사항은 미리 계획해 두는 것이 좋아요. 첫째, Opus 4.7은 업데이트된 토크나이저를 사용하여 텍스트 처리 방식을 개선했어요. 이로 인해 동일한 입력이 더 많은 토큰으로 매핑될 수 있는데, 콘텐츠 유형에 따라 약 1.0~1.35배 정도 더 사용될 수 있어요. 둘째, Opus 4.7은 특히 에이전틱 설정에서 후반부 턴에서 더 높은 노력 수준으로 더 많이 '생각'해요. 이는 어려운 문제에서 신뢰성을 향상시키지만, 더 많은 출력 토큰을 생성한다는 의미이기도 하죠.
사용자들은 노력 매개변수를 사용하거나, 태스크 예산을 조정하거나, 모델에 더 간결하게 응답하도록 프롬프트를 작성하는 등 다양한 방법으로 토큰 사용량을 제어할 수 있어요. 저희 자체 테스트에서는 순 효과가 긍정적이었어요. 아래에서 보듯이 모든 노력 수준에서 내부 코딩 평가에서의 토큰 사용량이 개선되었어요. 하지만 실제 트래픽에서 차이점을 측정해 보는 것을 권장해요. Opus 4.6에서 Opus 4.7로 업그레이드하는 데 대한 추가 조언을 제공하는 마이그레이션 가이드를 작성해 두었으니 참고해 주세요.
0
각주
1 이것은 API 매개변수라기보다는 모델 수준의 변경 사항이므로, 사용자가 Claude에게 보내는 이미지는 단순히 더 높은 충실도로 처리될 거예요. 고해상도 이미지는 더 많은 토큰을 소비하므로, 추가적인 디테일이 필요하지 않은 사용자들은 이미지를 모델에 보내기 전에 다운샘플링할 수 있어요.
- GPT-5.4 및 Gemini 3.1 Pro의 경우, 차트 및 표에서 API를 통해 사용 가능한 가장 좋은 보고 모델 버전을 비교했어요.
- MCP-Atlas: Opus 4.6 점수는 Scale AI의 수정된 채점 방법론을 반영하여 업데이트되었어요.
- SWE-bench Verified, Pro, 및 Multilingual: 저희의 암기 스크린은 이러한 SWE-bench 평가의 문제 중 일부를 플래그해요. 암기 흔적이 있는 문제는 제외하더라도 Opus 4.7의 Opus 4.6 대비 개선폭은 유지돼요.
- Terminal-Bench 2.0: 저희는 생각(thinking) 기능이 비활성화된 Terminus-2 하네스를 사용했어요. 모든 실험은 각 작업당 5번의 시도에 대해 1배 보장/3배 상한 자원 할당을 평균으로 사용했어요.
- CyberGym: Opus 4.6의 점수는 원래 보고된 66.6에서 73.8로 업데이트되었어요. 저희가 사이버 능력을 더 잘 이끌어내기 위해 하네스 매개변수를 업데이트했기 때문이죠.
- SWE-bench Multimodal: Opus 4.7과 Opus 4.6 모두에 내부 구현을 사용했어요. 점수는 공개 리더보드 점수와 직접 비교할 수 없어요.