DiffusionGemma: 개발자 가이드
요약
DiffusionGemma는 Gemma 4 기반의 새로운 텍스트 생성 모델로, 메모리 대역폭 대신 컴퓨팅으로 병목 현상을 전환하여 최대 4배 더 빠른 토큰 생성과 양방향 컨텍스트 기반의 자체 수정 능력을 제공하며, 효율적인 배포를 위한 MoE 아키텍처를 자랑해요.
인사이트
- DiffusionGemma는 메모리 대역폭 대신 컴퓨팅을 병목으로 활용해 GPU에서 최대 4배(초당 700~1000개 토큰) 빠른 토큰 생성을 가능하게 해요.
- 양방향 어텐션을 사용해서 전체 텍스트 블록을 동시에 평가하고 실시간 오류 수정 및 병렬 컨텍스트 전파를 통해 더 정확한 생성을 할 수 있어요.
- 26B 전문가 혼합(MoE) 모델이지만 추론 시에는 3.8B 파라미터만 활성화해서 18GB VRAM 내에서 양자화된 배포를 가능하게 해 개발자들이 쉽게 접근하고 활용할 수 있어요.
왜 중요한가
DiffusionGemma는 기존 LLM의 메모리 대역폭 한계를 극복하고 병렬 처리 방식을 도입하여 텍스트 생성 속도를 혁신적으로 높였어요. 이는 특히 비순차적이고 제약 조건이 많은 문제(예: 스도쿠)에서 강력한 성능을 보여줘요. 또한, 낮은 VRAM 요구사항으로 더 많은 개발자가 고성능 모델을 배포하고 활용할 수 있게 하여 생성형 AI 애플리케이션 개발에 큰 변화를 가져올 거예요.
2026년 6월 10일
이안 발렌타인, Google DeepMind 선임 개발자 관계 엔지니어
출시 블로그 게시물에서 발표한 내용을 이어서, Google DeepMind 팀은 이 실험적인 모델을 개발자분들이 이해하고, 서비스하며, 맞춤 설정하는 데 도움을 드리기 위해 이 개발자 가이드를 공유하려고 해요.
Gemma 4 백본을 기반으로 구축된 DiffusionGemma는 개발자 워크플로우를 위한 몇 가지 중요한 이정표를 제시해요.
- 컴퓨팅 중심의 병렬 생성: 병목 현상을 메모리 대역폭에서 컴퓨팅으로 옮겨서, GPU에서 최대 4배 더 빠른 토큰 생성을 제공해요. (NVIDIA GeForce RTX 5090에서 초당 700개 이상 토큰, 단일 NVIDIA H100에서 초당 1000개 이상 토큰을 처리해요.)
- 양방향 컨텍스트 및 자체 수정: 생성 중에 전체 텍스트 블록을 동시에 평가하기 위해 양방향 어텐션을 사용해서 실시간 오류 수정과 병렬 컨텍스트 전파를 가능하게 해요.
- 개발자 친화적인 크기: 26B 전문가 혼합(MoE) 모델로 설계되었고, 추론 시에는 3.8B 파라미터만 활성화해서 18GB VRAM 제한 내에서 양자화된 배포를 할 수 있게 도와줘요.
아키텍처
GPU에서 기존 LLM으로 개발하는 분들에게는 메모리 대역폭이 주요 병목 현상이에요. 오토리그레시브 언어 모델은 한 번에 하나의 토큰씩 텍스트를 생성하기 위해 메모리에서 모델 가중치를 반복적으로 로드해야 하죠. DiffusionGemma는 이 한계를 극복하기 위해 병목 현상을 메모리 대역폭에서 컴퓨팅으로 옮겨서 256 토큰 캔버스를 병렬로 생성하고 정제해요. GPU에 대규모 병렬 워크로드를 제공함으로써, 로컬 서빙 중에 유휴 상태로 있을 수 있는 텐서 코어를 활용하게 돼요.
- 균일 상태 확산(Uniform State Diffusion): 토큰을 순차적으로 예측하는 대신, DiffusionGemma는 무작위 자리표시 토큰으로 이루어진 캔버스에서 시작해서 이들을 병렬로 반복적으로 정제해요. 여러 번의 디노이징 과정을 거치면서, 높은 신뢰도를 가진 토큰들이 인접한 위치를 해결하는 데 도움을 줘서 전체 시퀀스가 한 번에 선명해지도록 해요.
- 가변 길이 생성을 위한 블록 오토리그레시브 확산(Block Autoregressive Diffusion for Variable Length Generation): 256 토큰보다 긴 시퀀스의 경우, 256 토큰 블록이 완전히 디노이징되면 모델은 이를 처리하고 KV 캐시에 커밋해요. 그런 다음 모델은 다음 블록으로 전환하고, 이전에 커밋된 이력을 조건으로 새로운 256 토큰 캔버스를 초기화해요. 이 방식은 병렬 블록의 속도와 오토리그레시브 모델의 순차적 안정성을 결합한 거예요.
사례: 병렬 디노이징으로 스도쿠 풀기
기존 오토리그레시브 모델은 스도쿠처럼 엄격하고 다변수 제약이 있는 문제에서는 어려움을 겪어요. 왼쪽에서 오른쪽으로만 텍스트를 생성하기 때문에 미래의 자리표시를 평가하거나 되돌릴 수 없기 때문이에요.
DiffusionGemma의 맞춤 설정을 시연하기 위해, Google DeepMind 팀은 모듈형 JAX 연구 툴박스인 Hackable Diffusion을 사용한 파인튜닝 레시피와 결과를 공개해요. 이 학습 설정은 고전적인 다변수 그리드 작업인 스도쿠 해결사에 초점을 맞추고 있어요.
스도쿠가 확산 모델에 흥미로운 이유
81자 스도쿠 문자열 표현(빈 셀은 마침표로 표시)에서 모든 숫자는 엄격하게 교차하는 가로, 세로, 9x9 그리드 제약에 묶여 있어요.
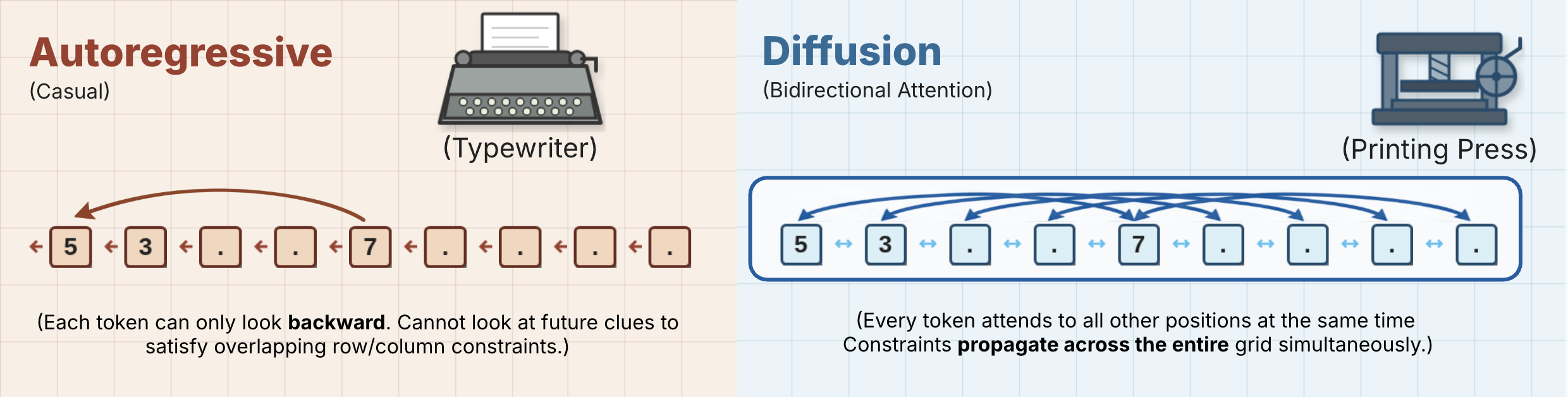
양방향 컨텍스트 전파: 오토리그레시브 모델과 달리, DiffusionGemma의 디노이징 단계는 모든 캔버스 쿼리가 모든 위치에 병렬로 어텐션하게 해줘요. 정보가 보드 전체에 대칭적으로 흐르면서 각 단계에서 전역적인 종속성을 해결해요.
- 재-노이징을 통한 오류 수정: 균일 상태 확산 방식에서는 모델이 전체 보드를 동시에 평가해요. 만약 신뢰도가 떨어지면, 샘플러가 숫자를 무작위 숫자로 교체해서 지속적인 자체 수정을 가능하게 해요.
- 효율적인 조기 중단: 스도쿠 파인튜닝 결과, 어댑터가 조기 중단을 향상시키는 것으로 나타났어요. SFT(Supervised Fine-Tuning) 튜닝된 모델이 기본 모델보다 더 빠르게 안정화되어서 엔진이 더 빨리 멈출 수 있고, 레이턴시와 컴퓨팅 비용을 줄여줘요.
Video 5 왼쪽: DiffusionGemma가 스도쿠 출력을 생성하는 모습이에요. 기본 모델은 48단계 후에도 스도쿠를 풀지 못하고 있어요. 오른쪽: 파인튜닝된(SFT) DiffusionGemma는 12단계 후에 퍼즐을 풀어요. 적응형 중단 덕분에 일찍 완료할 수 있어요.
성능 영향: 기본 DiffusionGemma 모델은 스도쿠 퍼즐을 풀도록 특별히 훈련되지 않았지만(~0% 성공률), 스도쿠 데이터셋에 간단한 JAX SFT 레시피를 적용하면 정확도가 80% 성공률로 높아지고 전체 추론 단계 수는 줄어들어요.
블록 오토리그레시브 디노이징
블록 오토리그레시브 디노이징을 가능하게 하기 위해 DiffusionGemma는 추론 중에 점진적인 프리필과 디노이징을 번갈아 수행해요.
- 프리필 / 점진적 프리필 (인과적): _인과적 어텐션_을 사용해서 프롬프트 컨텍스트를 받아들이고 KV 캐시에 기록해요. 이 과정은 초기 컨텍스트를 프리필하기 위해 한 번 실행되고, 다음 캔버스 디노이징으로 진행하기 전에 각 블록에서 최종화된 256 토큰 캔버스를 KV 캐시에 추가하기 위해 블록당 한 번씩 실행돼요.
- 디노이징 (양방향): _양방향 어텐션_을 사용해서 캔버스를 반복적으로 디노이징해요. 캔버스의 모든 위치에 있는 쿼리 토큰은 다른 모든 캔버스 토큰(및 KV 캐시)에 어텐션할 수 있어서, 모델이 컨텍스트를 양방향으로 처리할 수 있도록 해줘요.
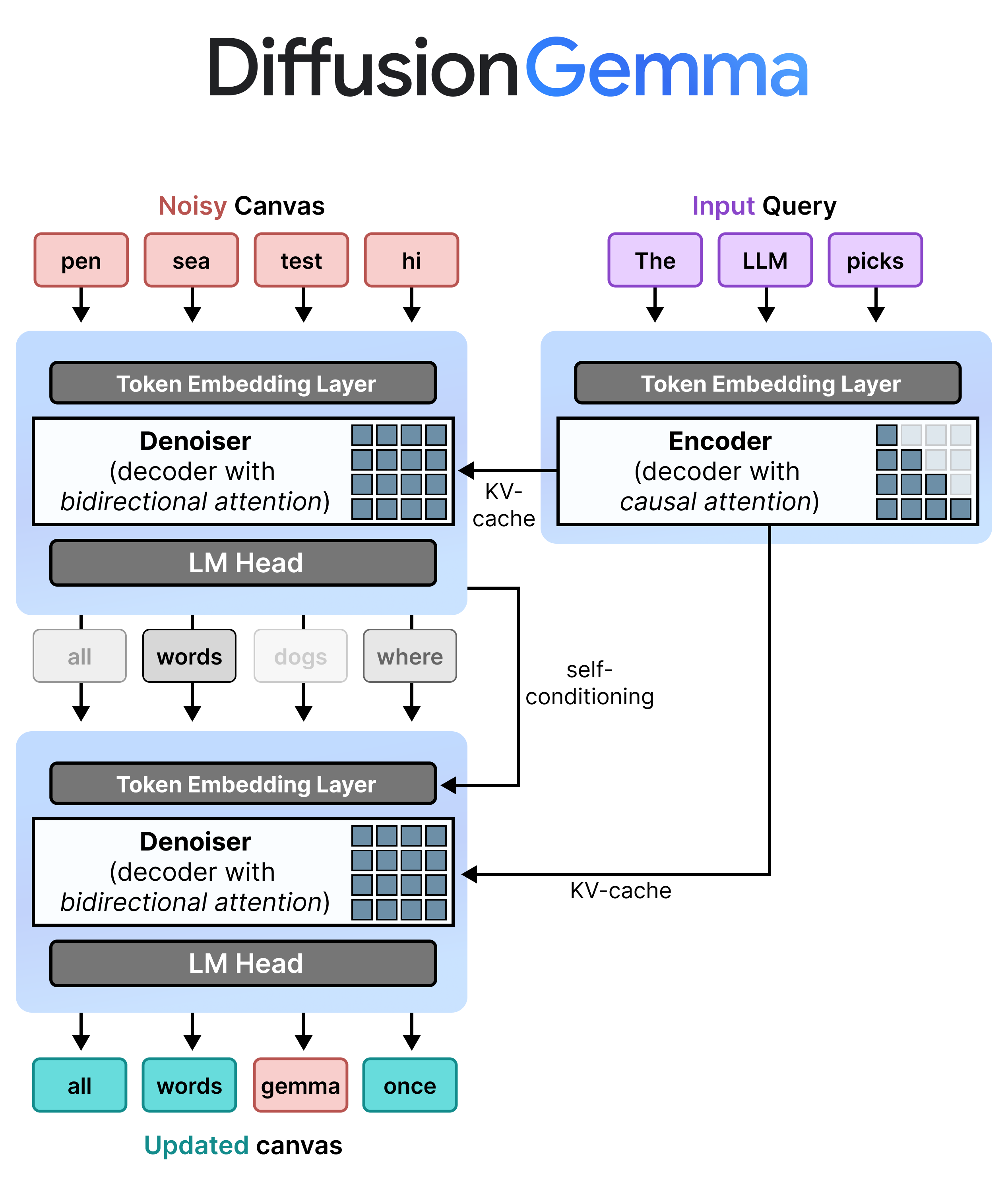
이러한 아키텍처 선택으로 다음이 가능해져요.
- 전역 컨텍스트 인식: '뒤만' 보는 오토리그레시브(AR) 모델과 달리, 디노이저의 양방향 어텐션은 캔버스의 모든 토큰이 다른 모든 토큰에 어텐션할 수 있도록 해줘요. 이 덕분에 모델은 첫 번째 셀의 숫자가 마지막 셀의 제약을 준수해야 하는 스도쿠와 같은 비순차적 문제를 훨씬 더 효과적으로 해결할 수 있어요.
- 자체 수정: 모델이 전체 캔버스를 반복적으로 정제하기 때문에, 이전에 발생한 실수를 '고칠' 수 있어요. 한 토큰의 신뢰도가 패스 중에 떨어지면, 샘플러가 다시 노이즈를 추가하고 교체할 수 있어요. 이는 AR 모델에는 없는 기능인데, AR 모델은 일단 토큰이 생성되면 특히 긴 출력 시퀀스에서 '고정'되기 때문이에요.
- 효율적인 긴 컨텍스트 확장: '블록-오토리그레시브' 접근 방식은 모델이 긴 시퀀스를 처리할 수 있도록 해줘요. 이는 블록에 대한 확산의 병렬 속도와 긴 형식 텍스트에 대한 AR 모델의 검증된 순차적 안정성을 결합한 거예요.
- 간소화된 배포: Gemma 4 26B A4B 모델과 동일한 아키텍처를 사용한다는 것은 개발자가 디노이징 단계만 구현하면 된다는 것을 의미해요. 덕분에 vLLM과 같은 기존 서빙 프레임워크에 더 쉽게 통합할 수 있어요.
DiffusionGemma 서비스하기
이 실험적인 아키텍처를 효율적으로 서비스하기 위해, Google 팀은 vLLM 팀과 협력해서 DiffusionGemma를 vLLM에 구현했어요. 이 통합 덕분에 엔진은 배치된 요청 스트림 전반에 걸쳐 반복적인 병렬 디노이징 루프를 효율적으로 실행할 수 있어요.
개발자분들은 vLLM의 표준 OpenAI 호환 로컬 서버를 사용해서 DiffusionGemma를 바로 배포할 수 있어요.
vllm serve google/diffusiongemma-26B-A4B-it \
--max-model-len 262144 \
--max-num-seqs 4 \
--gpu-memory-utilization 0.85 \
--attention-backend TRITON_ATTN \
--generation-config vllm \
--hf-overrides '{"diffusion_sampler": "entropy_bound", "diffusion_entropy_bound": 0.1}' \
--diffusion-config '{"canvas_length": 256}' \
--enable-chunked-prefill
Shell
복사됨
오늘 바로 시작하기
비-오토리그레시브 텍스트 생성의 최전선을 탐험할 준비가 되셨나요? 더 자세한 정보를 얻으려면 다음 자료들을 확인해 보세요.
- 가중치 다운로드: 실험 모델의 가중치(Apache 2.0 라이선스에 따라 출시)를 Hugging Face에서 직접 이용할 수 있어요.
- 통합 및 학습: DiffusionGemma 시각 가이드를 확인해서 텍스트 기반 확산 모델의 작동 방식을 이해해 보세요. Gemma 문서에서 DiffusionGemma에 대해 더 자세히 읽어볼 수도 있어요.
- 자주 사용하는 추론 프레임워크 활용: vLLM, Hugging Face Transformers, SGLang, 그리고 MLX를 사용해서 모델을 효율적으로 실행해 보세요.
- 적응 및 파인튜닝: 빠른 실험을 위해, Google 팀은 Hackable Diffusion을 사용한 공식 학습 레시피를 공개하고 있어요. Unsloth 또는 NVIDIA NeMo를 사용한 효율적인 파인튜닝도 탐색할 수 있어요.
- 원하는 방식으로 배포: Model Garden을 사용해서 Google Cloud에 즉시 배포하거나 NVIDIA NIM을 통해 배포할 수 있어요. 이 모델은 소비자용 RTX 4090 및 5090 카드부터 엔터프라이즈 Hopper 및 Blackwell 서버에 이르기까지 하드웨어 스택 전반에 걸쳐 기본적으로 최적화되어 있어요.
다음