LiteRT-LM으로 초고속 온디바이스 생성형 AI 구현하기
요약
Google AI Edge의 LiteRT-LM은 Gemma 4 모델을 활용하여 다양한 플랫폼에서 초고속 온디바이스 생성형 AI를 구현할 수 있도록 최적화된 솔루션을 제공하고, 개발자들이 프라이버시를 지키면서 저지연 애플리케이션을 쉽게 구축할 수 있게 도와줘요.
인사이트
- **최첨단 온디바이스 성능**: LiteRT-LM은 Google AI Edge 스택을 활용하여 Gemma 4 모델의 최적화된 성능을 Android, iOS, 웹 등 다양한 엣지 기기에서 제공하며, XNNPACK, MLDrift 커널과 고급 양자화 기법으로 메모리 및 연산 제약을 극복해요.
- **독보적인 속도 향상 기술**: Multi-Token Prediction (MTP)을 통합하여 최대 2.2배의 추론 속도 향상을 이루었고, 효율적인 세션 관리로 컨텍스트 연속성을 보장하며, 동적 메모리 활용 최적화로 최소한의 설치 공간에서 Gemma 4를 실행할 수 있어요.
- **강력한 에이전틱 기능 및 폭넓은 개발 지원**: 사고 모드(Thinking Mode)를 통해 모델의 추론 품질을 높이고, 제약 디코딩(Constrained Decoding)으로 구조화된 출력을 보장하며, 함수 호출(Function Calling) 기능을 네이티브로 지원해요. 또한 Swift 및 JavaScript API를 제공하여 다양한 플랫폼의 개발자들이 쉽게 온디바이스 AI를 통합할 수 있도록 지원하고 있어요.
왜 중요한가
LiteRT-LM은 개발자들이 복잡한 하드웨어 및 플랫폼의 차이점을 걱정하지 않고, 최신 대규모 언어 모델(LLM)인 Gemma 4를 활용해 프라이버시를 보호하면서도 매우 빠르고 강력한 에이전틱 기능을 갖춘 온디바이스 애플리케이션을 쉽게 만들 수 있도록 해줘요. 이는 엣지 AI의 새로운 가능성을 열고 사용자 경험을 크게 향상시킬 거예요.
2026년 5월 19일
첨단 AI를 엣지 기기에 가져오는 일에 있어서, Google AI Edge의 LiteRT-LM은 Gemma 4를 다양한 플랫폼에 배포할 수 있는 가장 강력하고 최적화된 경험 중 하나를 제공하고 있어요. LiteRT (이전 TensorFlow Lite)를 활용해서 추론을 수행하는 LiteRT-LM은 Chrome, ChromeOS, Pixel Watch 같은 수많은 구글 제품들과 최근 엄청난 인기를 끈 Google AI Edge Gallery 앱(Android / iOS)에서 로컬 AI를 구현할 수 있게 해줘요. Gemma 4로 최첨단 에이전틱 기능을 구현하는 것부터 까다로운 프로덕션 사용 사례를 확장하는 것까지, 이 검증된 엔진이 이제 여러분의 애플리케이션에 힘을 실어줄 준비가 됐어요. 지금부터 핵심 스택과 LiteRT-LM을 여러분의 엣지 LLM 배포에 어떻게 활용할 수 있는지 자세히 알아볼게요.
최첨단 성능
Gemma 4를 온디바이스에서 온전히 활용하기 위해, 구글은 Google AI Edge 스택을 활용하고 있어요. 이 스택은 다양한 플랫폼에서 Gemma 4를 실행하는 가장 성능 좋은 방법이에요 (훨씬 더 나은 성능을 원한다면 Android AICore를 통해 Gemma 4를 시스템 서비스로 실행할 수도 있어요). 제한된 메모리, 한정된 컴퓨팅 자원, 그리고 파편화된 하드웨어라는 상반된 요구 사항들을 처리하기 위해, 이 스택은 가속화된 XNNPACK 및 MLDrift 커널을 기반으로 고급 양자화 기법들을 지원하고 있어요. 이렇게 효율적인 설치 공간(footprint)을 LiteRT 런타임과 결합해서, 이 스택은 CPU, GPU, NPU 백엔드 전반에 걸쳐 모델을 매끄럽게 실행하고 넓은 휴대성(portability)을 가능하게 해줘요. 마지막으로, 오케스트레이션 계층에서는 LiteRT-LM이 최적화된 파이프라인을 활용해서 비용이 많이 드는 CPU/GPU 데이터 전송을 피하고, 멀티 토큰 예측 (Multi-Token Prediction, MTP)과 고급 세션 관리를 함께 사용하고 있어요. 이 모든 완전한 통합이 Gemma 모델을 위한 최고 성능의 런타임 환경을 제공하고 있어요.
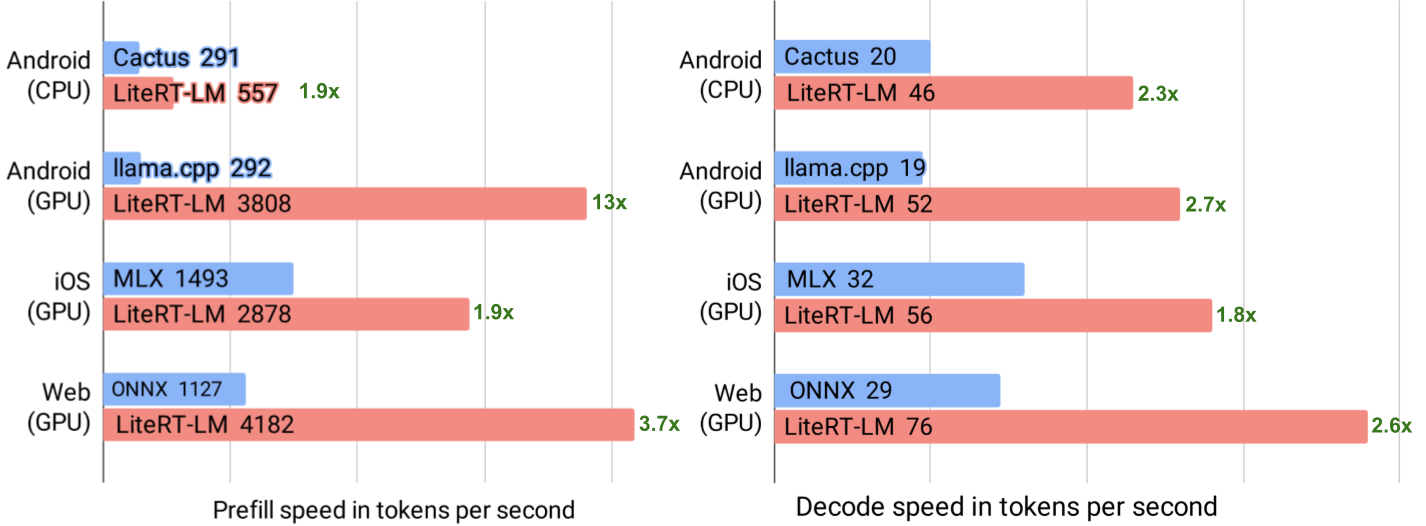
LiteRT-LM Gemma 4 E2B 선행 처리 및 디코딩 성능 (Android: Samsung S26 Ultra, iOS: iPhone 17 Pro, Web: MacBook Pro 2024 Apple M4 Max에서 Chrome 실행).
다양한 하드웨어 백엔드 및 플랫폼에서 속도를 위해 구축됐어요
LiteRT-LM은 전체 엣지 생태계에서 뛰어난 성능을 제공하도록 설계되어 Android, iOS, 그리고 개방형 웹에서 낮은 레이턴시 추론을 보장하고 있어요. 이를 달성하기 위해, 런타임은 LiteRT를 통해 CPU, GPU, NPU (현재 Android에서만 지원)를 이용한 가장 최적화된 하드웨어 백엔드 최적화를 매끄럽게 가속화해요. 이 접근 방식을 통해 개발자들은 한 번만 구축하고 모든 곳에서 최고의 성능을 달성할 수 있어요:
- MTP를 활성화하지 않고 Gemma 4 E2B를 실행할 때, LiteRT-LM은 Android (OpenCL)의 GPU 백엔드에서 인상적인 초당 52 토큰의 디코딩 속도를 달성하고, iOS (Metal)에서는 초당 56 토큰을 달성해요.
- WebGPU를 사용하는 웹에서는 개발자들이 Macbook Pro에서 최대 초당 76 토큰의 디코딩 속도를 기대할 수 있어요. 이는 사용자의 플랫폼이나 하드웨어에 관계없이 최첨단 온디바이스 AI가 이제 현실이 되었음을 증명하고 있어요.
최고 처리량을 위한 멀티 토큰 예측 (MTP)
LiteRT-LM 파이프라인에서 가장 중요한 성능 개선점 중 하나는 Gemma 4 모델군과 함께 최근 출시된 멀티 토큰 예측 (MTP) 드래프터에 대한 네이티브 지원이에요. 이 특수 투기적 디코딩 아키텍처를 통합함으로써, LiteRT-LM은 전통적인 레이턴시 병목 현상을 우회해서 최대 2.2배의 속도 향상을 제공해요.
표준 LLM 추론은 기본적으로 메모리 대역폭에 의해 제한돼요. 프로세서는 단일 토큰을 생성하기 위해 수십억 개의 파라미터를 VRAM에서 컴퓨팅 유닛으로 이동하는 데 대부분의 시간을 소비해요. 투기적 디코딩이 이 문제를 완화하지만, 순진한 구현은 새로운 병목 현상을 초래할 수도 있어요. LiteRT-LM은 주 Gemma 4 모델과 MTP 드래프터 사이의 데이터 상호 작용을 최적화해서 이런 문제를 막아줘요.
이를 달성하기 위해 LiteRT-LM은 경량 MTP 드래프터와 주 모델을 동일한 하드웨어 IP (예: GPU)에서 실행함으로써 메모리 지역성(memory locality)을 강화하고 있어요. 공유 KV 캐시와 활성화(activations)를 로컬 메모리 내에서 관리함으로써 교차 IP 동기화 및 데이터 전송으로 인한 레이턴시 손실을 완전히 제거해요. 드래프터가 미래 토큰을 예측하면, 주 모델은 검증 과정에서 병렬화를 극대화하는 최적화된 커널을 사용해서 이를 평가하고 있어요. 이렇게 효율적으로 간소화된 아키텍처는 추론 품질을 잃지 않으면서 멀티 토큰 처리량을 가속화해요.

LiteRT-LM 파이프라인에서 MTP를 활성화하는 데는 단 두 줄의 설정만 필요하며, 저지연 애플리케이션에서 즉시 최대 2.2배의 디코딩 속도 향상을 얻을 수 있어요. 보고된 수치는 Samsung S26 Ultra에서 GPU 백엔드를 사용하여 수집되었어요.
속도와 연속성을 위한 세션 관리
LiteRT-LM의 고급 세션 관리는 모바일 애플리케이션이 긴 컨텍스트 상호 작용을 처리하는 방식을 근본적으로 변화시키고 있어요. 네이티브 세션 저장 및 복원 기능을 지원함으로써, 이 엔진은 더 긴 컨텍스트 기록을 나타내는 대규모 KV 캐시 상태를 직렬화해서 세션 전반에 걸쳐 안전하게 보존할 수 있게 해줘요. 이 아키텍처는 대화나 워크플로우를 매끄럽게 재개할 수 있도록 보장해서 사용자 경험의 연속성을 매끄럽게 이어줘요. 사용자 경험 이점 외에도, 이 메커니즘은 백엔드 효율성을 높여줘요. 컨텍스트 상태를 보존하면 중복 계산의 필요성이 줄어들고, 다시 접속하는 세션에서 무거운 선행 처리(prefill) 단계를 우회할 수 있어요. 이 효율성은 Google AI Edge Gallery 앱의 확장된 에이전트 스킬과 같은 동적 기능에 힘을 실어주면서, 전반적인 컴퓨팅 비용을 절감하고 놀랍도록 빠른 엔드투엔드 온디바이스 경험을 제공하고 있어요.
효율적인 메모리 활용
Gemma 4의 네이티브 비전 및 오디오 기능을 온디바이스에 매끄럽게 배포하기 위해, LiteRT-LM은 엄격한 하드웨어 제약 조건 내에서 효율성을 극대화하는 고급 메모리 설치 공간 최적화를 사용하고 있어요. 런타임은 계층별 임베딩(Per-Layer Embeddings, PLEs)을 메모리에서 제외하고 특정 작업이 필요할 때만 이미지 및 오디오 인코더를 동적으로 로드함으로써 오버헤드를 전략적으로 줄여요. 이를 통해 텍스트 전용 워크로드가 매우 가볍게 유지되도록 보장하고 있어요. LiteRT-LM은 또한 CPU 실행을 위한 전반적인 메모리 소비를 고도로 최적화해서 개발자들이 최소한의 디바이스 설치 공간을 유지하면서 강력한 성능을 달성할 수 있도록 해줘요. 구체적인 메모리 벤치마크는 공식 모델 카드(E2B, E4B)에서 확인해 보세요.
이러한 기술들을 결합한 결과, 런타임 설치 공간이 매우 가벼워졌어요. 예를 들어, LiteRT-LM은 XNNPACK의 가중치 캐싱 메커니즘을 활용해서 약 2.58GB 크기의 Gemma 4 E2B 모델을 애플 모바일 CPU에서 단 607MB의 실제 메모리 설치 공간으로 성공적으로 실행하고 있어요. 이렇게 활성 메모리 오버헤드가 줄어들면서 앱의 전반적인 안정성을 해치지 않으면서도 강력하고 기업 수준의 AI 성능을 보장해줘요.
에이전틱 워크플로우 오케스트레이션: 사고, 포맷, 실행
모델이 외부 작업을 트리거하기 전에 매우 복잡한 다단계 작업을 실행할 수 있도록 보장하기 위해, LiteRT-LM은 **사고 모드 (Thinking Mode)**를 네이티브로 지원하고 있어요 (Gemma 4 모델군에서 사용 가능해요). 모델이 작업을 확정하기 전에 단계별 추론을 위한 스크래치패드를 할당함으로써, LiteRT-LM은 출력 품질을 크게 향상시킬 수 있어요. 개발자들은 이 원시적인 추론 과정을 UI에 직접 스트리밍하거나, 멀티턴 모바일 세션에서 중요한 KV 캐시 공간을 절약하기 위해 이 과정을 제거할 수도 있어요.
모델이 내부 추론을 마친 후에는 출력을 구조화하는 것이 중요해요. 강력한 제약 디코딩 (constrained decoding, CD)과 함께, 개발자들은 최종적으로 생성된 도구 페이로드에 엄격한 JSON 스키마나 특정 출력 문법을 강제해서 파서 오류를 완전히 제거할 수 있어요.

사고 모드 + 제약 디코딩 지원으로 인한 품질 향상 (Samsung S25 Ultra CPU 기준).
깊은 사고와 엄격한 경계가 설정되면, 모델은 이제 행동할 준비가 됐어요. 단순한 생성 기능을 넘어, LiteRT-LM은 FunctionGemma에서 도입되고 Gemma 4에서 완벽해진 네이티브 함수 호출 기능을 지원해요. 런타임은 실행을 매끄럽게 일시 중지하고, 구조화된 도구 호출 요청을 애플리케이션 계층으로 반환한 다음, 도구의 출력을 받으면 다시 실행을 재개해요.
통합 범위 확장
LiteRT-LM은 처음부터 크로스 플랫폼을 목표로 구축되었고, 현재 Android 지원(Kotlin/C++)을 넘어 Apple 생태계(Swift API) 및 개방형 웹(JavaScript API)을 위한 새로운 인터페이스로 확장하고 있어요.
Swift를 이용한 네이티브 개발
Gemma 모델을 위한 최첨단 성능을 확장하면서, LiteRT-LM은 이제 완전 오픈소스 iOS Swift API를 통해 네이티브 Apple 개발을 가능하게 해주고 있어요.

iOS Swift용 LiteRT-LM과 MLX의 성능 비교 (iPhone 17 Pro 테스트 기준).
WebGPU를 이용한 고성능 브라우저 추론
구글은 LiteRT-LM의 강력한 기능을 브라우저에도 가져오고 있어요. 이 생산성 검증된 추론 파이프라인은 이제 구글의 자바스크립트 API를 통해 웹(WASM)에서 완전히 접근할 수 있어요. WebGPU 기반으로, LiteRT-LM은 클라이언트 측에서 번개처럼 빠른 LLM 라우팅 및 실행을 제공해서 서버리스, 보안, 그리고 완벽한 개인 정보 보호 웹 애플리케이션을 가능하게 해줘요. MediaPipe LLM 추론 엔진의 웹 솔루션의 기반이 되는 성공을 바탕으로, LiteRT-LM의 네이티브 웹 지원은 구글 온디바이스 AI 스택의 다음 진화를 나타내고 있어요.
Video 9 LiteRT-LM 웹 데모는 Apple MacBook Pro M3 36GB (18 GPU 코어)에서 실행되고 있어요.
구글의 웹 솔루션은 다른 웹 기반 LLM 프레임워크에 비해 상당한 성능 향상을 제공해요.

LiteRT-LM.js와 ONNX Runtime Web의 성능 비교 (MacBook Pro 2024 Apple M4 Max 48GB, 40 GPU 코어, Chrome 테스트 기준).
앞으로의 전망
강력한 LLM 추론과 진정한 에이전틱 기술을 엣지 기기에 가져왔을 때 무엇이 가능한지에 대한 가능성은 이제 막 시작에 불과해요. LiteRT-LM은 메모리, 하드웨어 가속, 그리고 크로스 플랫폼의 특이성(idiosyncrasies)을 관리하는 번거로움을 없애서 여러분이 차세대 프라이버시 우선, 제로 레이턴시 애플리케이션을 구축할 수 있도록 해줘요.
여러분도 직접 사용해 보셨으면 좋겠어요. 데스크톱용 LiteRT-LM CLI나 모바일용 AI Edge Gallery를 다운로드하거나, 지금 바로 코드와 API를 확인해 보세요. 여러분이 어떤 멋진 것을 만들지 정말 기대돼요!
감사의 말씀
구글은 이 프로젝트의 핵심 기여자들인 다음 분들께 깊은 감사를 전하고 싶어요: Advait Jain, Alice Zheng, Cormac Brick, Byungchul Kim, Fengwu Yao, Jae Yoo, Jenn Lee, Lu Wang, Marissa Ikonomidis, Matthew Chan, Matthew Soulanille, Matthias Grundmann, Mohammadreza Heydary, Ram Iyengar, Sachin Kotwani, Salil Tambe, Suleman Shahid, Tenghui Zhu, Tyler Mullen, Vinod Mamillapalli, Wai Hon Law, Weiyi Wang, Yi-Chun Kuo, Yu-hui Chen.
이 발표 내용과 모든 Google I/O 2026 업데이트는 io.google에서 확인해 보세요.
다음