구글 TPU에서 LLM 추론 가속화: 확산 스타일 투기적 디코딩으로 3배 속도 향상 달성
요약
구글 TPU에서 LLM 추론 속도를 획기적으로 개선하기 위해, UCSD 연구팀이 기존 투기적 디코딩의 병목 현상을 해결하는 '확산 스타일 투기적 디코딩(DFlash)'을 구현하여 평균 3.13배, 특정 작업에서는 최대 6배까지 빠른 속도를 달성했어요.
인사이트
- 기존의 순차적(O(K)) 투기적 디코딩과 달리, 확산 스타일 투기적 디코딩(DFlash)은 전체 토큰 블록을 한 번에 생성(O(1))하여 추론 속도의 근본적인 병목을 해소했어요.
- 고성능 TPU에서는 대량의 토큰을 검증하는 비용이 적은 토큰을 검증하는 비용과 거의 같다는 'K-Flat 검증' 현상이 발견되어, 이제 투기적 디코딩의 병목은 검증 비용이 아니라 초안의 품질로 바뀌었어요.
- 수학이나 코딩처럼 예측 가능한 작업에서 확산 스타일 디코딩의 효과가 가장 크며, 이는 초안 토큰의 수량보다 품질과 작업의 예측 가능성이 전체 시스템 속도 향상에 더 중요하다는 것을 보여줘요.
왜 중요한가
이번 연구는 대규모 언어 모델(LLM)의 추론 속도를 획기적으로 향상시킬 수 있는 새로운 패러다임을 제시합니다. 특히 구글 TPU와 같은 고성능 하드웨어의 잠재력을 최대한 활용하여, LLM 서비스의 레이턴시를 줄이고 처리량을 늘릴 수 있다는 점에서 매우 중요해요. 이는 복잡한 AI 모델을 실시간 애플리케이션에 적용하는 데 큰 도움이 될 거에요.
구글 TPU에서 LLM 추론 가속화: 확산 스타일 투기적 디코딩으로 3배 속도 향상 달성 - Google Developers Blog

개발
성장
수익
그룹
프로그램
스토리
검색
-
- 더 보기
-
- 더 보기
개발
성장
수익
그룹
프로그램
스토리
구글 TPU에서 LLM 추론 가속화: 확산 스타일 투기적 디코딩으로 3배 속도 향상 달성
2026년 5월 4일
Weiren Yu 제품 매니저
Yarong Mu 수석 스태프 소프트웨어 엔지니어, Google Cloud
Lihao Ran 소프트웨어 엔지니어, Google Cloud
Zhaoxiang Feng 연구 조교, UCSD
Yiming Zhao 연구 조교, UCSD
Hao Zhang 조교수, UCSD
공유

현재 LLM(대규모 언어 모델) 가속화 분야는 자기회귀 투기적 디코딩(autoregressive speculative decoding)이 주도하고 있어요. 여기서 경량 드래프터(drafter)는 타겟 모델이 검증하기 전에 토큰을 순차적으로 예측하죠. 하지만 이런 순차적인 초안 생성 방식은 근본적인 실행 병목 현상을 일으켜요. K개의 후보 토큰을 생성하려면 K번의 순차적인 정방향 패스가 필요하기 때문이에요. 이 단계별 의존성 때문에 시스템은 다음 토큰 예측을 시작하기 전에 각 토큰이 예측될 때까지 기다려야 해서, 초안 생성 단계의 속도 향상 잠재력을 본질적으로 제한하게 돼요. 이 효율성 한계를 깨기 위해, 연구팀은 토큰별 초안 생성을 넘어 **블록 확산(block diffusion)**으로 나아가고 있어요. 이는 전체 후보 토큰 블록을 O(1) 단일 정방향 패스로 생성할 수 있게 해주는 패러다임 전환이랍니다.
구글은 AI 하드웨어의 한계를 뛰어넘는 외부 연구자들을 지원하게 된 것을 자랑스럽게 생각해요. 오늘, 구글은 paged attention과 prefill/decode disaggregated serving의 공동 발명가인 Hao Zhang 교수가 이끄는 UCSD 연구팀의 중요한 오픈소스 성과를 소개하게 되어 정말 기뻐요. 이 연구팀은 블록 확산 투기적 디코딩(즉, DFlash, Zhijian Liu, Jian Chen 등이 UCSD의 Z Lab에서 개발한 우수한 확산 스타일 투기적 디코딩)을 구글 TPU에 성공적으로 구현했어요.
이 새로운 아키텍처를 오픈소스 vLLM TPU 추론 생태계에 직접 통합함으로써, UCSD 팀은 TPU v5p에서 초당 토큰 처리량을 평균 3.13배 증가시켰어요. 특히 복잡한 수학 작업에서는 최고 속도가 거의 6배에 달했죠. DFlash와 EAGLE-3 간의 TPU v5p에서 직접적인 서빙 성능 비교에서, DFlash는 2.29배의 전체 서빙 속도 향상을 달성했는데, 이는 EAGLE-3의 1.30배 성능 향상보다 거의 두 배에 달하는 수치에요.
여기 UCSD 연구팀이 어떻게 이걸 구축했는지, 그들의 성능 벤치마크, 그리고 이것이 구글 TPU 생태계의 미래에 어떤 의미를 가지는지에 대한 기술적인 심층 분석이 있어요.
자기회귀 병목 현상 극복하기
표준 LLM 추론은 텍스트를 자기회귀적으로 생성해요. 이는 모델이 생성되는 토큰 하나하나마다 전체 정방향 패스를 필요로 한다는 뜻이에요. 이 때문에 특히 배치 크기가 작을 때, TPU와 같은 AI 가속기의 엄청난 병렬 컴퓨팅 능력이 제대로 활용되지 못하는 문제가 있었죠.
**투기적 디코딩(speculative decoding)**은 더 작고 효율적인 "초안(draft)" 모델(또는 메커니즘)을 사용하여 여러 미래 토큰을 동시에 예측함으로써 이 문제를 완화해요. 그런 다음 더 큰 "타겟(target)" 모델이 이 초안 토큰들을 단일 병렬 정방향 패스로 검증하죠. 만약 초안 토큰이 정확하면, 시스템은 단일 단계 비용으로 여러 토큰을 받아들여 레이턴시를 획기적으로 줄일 수 있어요.
하지만 투기적 디코딩의 잠재력은 종종 초안 모델 자체에 의해 제약을 받았어요. 대부분의 기존 방법은 후보 토큰을 순차적으로 생성하는 자기회귀 초안 메커니즘에 의존하죠. 이는 타겟 모델의 검증은 병렬로 이루어지지만, 초안 생성 단계는 여전히 O(K) 순차적 단계에 의해 병목 현상이 발생한다는 것을 의미해요. 그 결과, 토큰을 "추측하는" 데 드는 시간이 검증으로 절약되는 시간을 잠식하기 시작하여 실제 속도 향상 잠재력을 제한했어요.
구글 TPU에서의 확산 스타일 초안 생성
dLLM(확산 LLM)은 이 순차적인 프로세스를 블록 확산 메커니즘으로 대체하여 게임의 판도를 근본적으로 바꿔놓았어요. 다음 단어를 추측하는 대신, dLLM은 전체 블록을 "그려내죠." 주목할 만한 dLLM 기반 초안 생성 방법이 바로 DFlash에요. DFlash는 타겟 모델에서 추출한 은닉 특징을 활용하여 단일 정방향 패스로 전체 초안 토큰 블록을 생성할 수 있어요. *O(K)*에서 O(1) 복잡도로의 이러한 전환은 초안 생성 레이턴시를 거의 무시할 수 있는 수준으로 줄여주어, TPU의 고대역폭 행렬 곱셈 장치(MXU)에 완벽하게 적합한 아키텍처가 되었답니다.
UCSD 연구팀은 DFlash를 vLLM TPU 추론 프레임워크에 통합했어요. DFlash는 블록 확산 메커니즘을 활용하여 매우 높은 승인 길이(T)로 초안 토큰을 제안하는 투기적 디코딩의 새로운 접근 방식이에요.
이를 구글 TPU에 구현하려면 깊이 있는 최적화가 필요했어요. 구글 클라우드 엔지니어들의 아키텍처적 지도를 받으며, UCSD 팀은 메모리 대역폭과 행렬 곱셈 장치가 완전히 포화되도록 오버헤드를 최소화했답니다. DFlash 제안자와 검증 파이프라인을 TPU 아키텍처에 효율적으로 매핑함으로써, 초안 생성 단계의 오버헤드를 최소화하고 타겟 모델의 병렬 검증 처리량을 극대화했어요.
TPU/JAX로 DFlash 가져오기
DFlash를 원래의 GPU/PyTorch 구현에서 구글 TPU/JAX AI 스택 생태계로 포팅하는 것은 단순한 코드 번역을 넘어, TPU의 고유한 아키텍처적 강점에 맞춰 시스템을 재설계하는 작업이었어요. UCSD 팀이 세 가지 주요 기술적 난관을 어떻게 해결했는지 살펴볼게요.
어텐션을 위한 "듀얼 캐시" 솔루션
PyTorch 환경에서 DFlash는 간단하고 동적인 KV 관리에 의존해요. 하지만 tpu-inference를 통한 고성능 TPU 서빙은 효율성을 극대화하기 위해 메모리를 고정 크기 페이지로 나누는 Pallas 커널과 함께 paged attention을 사용하죠.
문제는 DFlash의 비인과적 블록 확산, 즉 토큰 블록을 "그려낼" 수 있게 해주는 바로 그 기능이 표준 paged attention과 근본적으로 호환되지 않는다는 것이었어요. 이 문제를 해결하기 위해, 연구팀은 듀얼 캐시 아키텍처를 설계했답니다. 타겟 모델은 paged KV 캐시를 계속 사용하여 대규모 서빙에 필요한 고성능 Pallas 커널의 이점을 누릴 수 있도록 했어요. 초안 모델은 정적 온디바이스 JAX 배열을 사용하는 특수 경로를 사용하여, 원래 DFlash 설계를 성공적으로 모방하면서도 TPU 고유의 성능을 유지할 수 있었어요.
지능형 컨텍스트 관리
DFlash는 초안 모델이 타겟 모델의 중간 추론 단계를 "관찰"하여 똑똑하게 작동한다는 점에서 독특해요. 이러한 "은닉 상태"는 시간이 지남에 따라 커지는 컨텍스트 버퍼에 저장돼요.
호스트 CPU와 TPU 가속기 간의 통신을 최대한 빠르게 유지하기 위해, 팀은 2의 거듭제곱 패딩 전략을 구현했어요. 이는 새로 투영된 특징이 버퍼에 추가될 때 최적화된 청크로 전송되도록 보장해요. 초안 모델이 이미 "소비한" 컨텍스트의 양을 면밀히 추적함으로써, 중복 처리나 데이터 손실을 방지하고 병렬 초안 생성을 매우 정확하게 유지할 수 있었어요.
TPU 추론의 메타데이터 격차 해소
표준 초안 생성 방법과 달리, DFlash는 고유하게 상태를 가지며, 반복마다 영구적인 상태(컨텍스트 버퍼, KV 캐시 위치, RoPE 오프셋 포함)에 의존하여 병렬 블록 예측을 유지해요. TPU 최적화 vLLM 파이프라인에서, 제안자로 전달되는 메타데이터에는 현재 검증 중인 초안 토큰이 포함되었어요. 이는 대부분의 모델에서는 표준적이지만, 확산 기반 아키텍처에서는 "시퀀스 길이 인플레이션"이라는 결과를 낳았죠. 이는 내부 초안 상태가 타겟 모델의 실제와 어긋나는 현상이에요.
연구팀은 제안자를 재설계하여 실제 승인된 토큰 수와 엄격하게 동기화함으로써 두 모델 간의 완벽한 **정렬(alignment)**을 복구했어요. 이 조정 덕분에 블록 확산 로직이 TPU 하드웨어에서 완전한 수학적 정밀도로 작동할 수 있었고, 최종 결과에서 보이는 엄청난 속도 향상을 이끌어낼 수 있었답니다.
TPU 서빙의 미래 벤치마킹
정면 대결: TPU v5p에서 DFlash vs. EAGLE-3
엄격하고 공정한 비교를 위해, UCSD 연구팀은 TPU에서 현재 주류인 투기적 디코딩 방법인 EAGLE-3와 DFlash를 벤치마킹했어요. 이 비교 연구에서 연구팀은 동일한 하드웨어(TPU v5p)와 동일한 타겟 모델(Llama-3.1-8B)을 사용했어요.
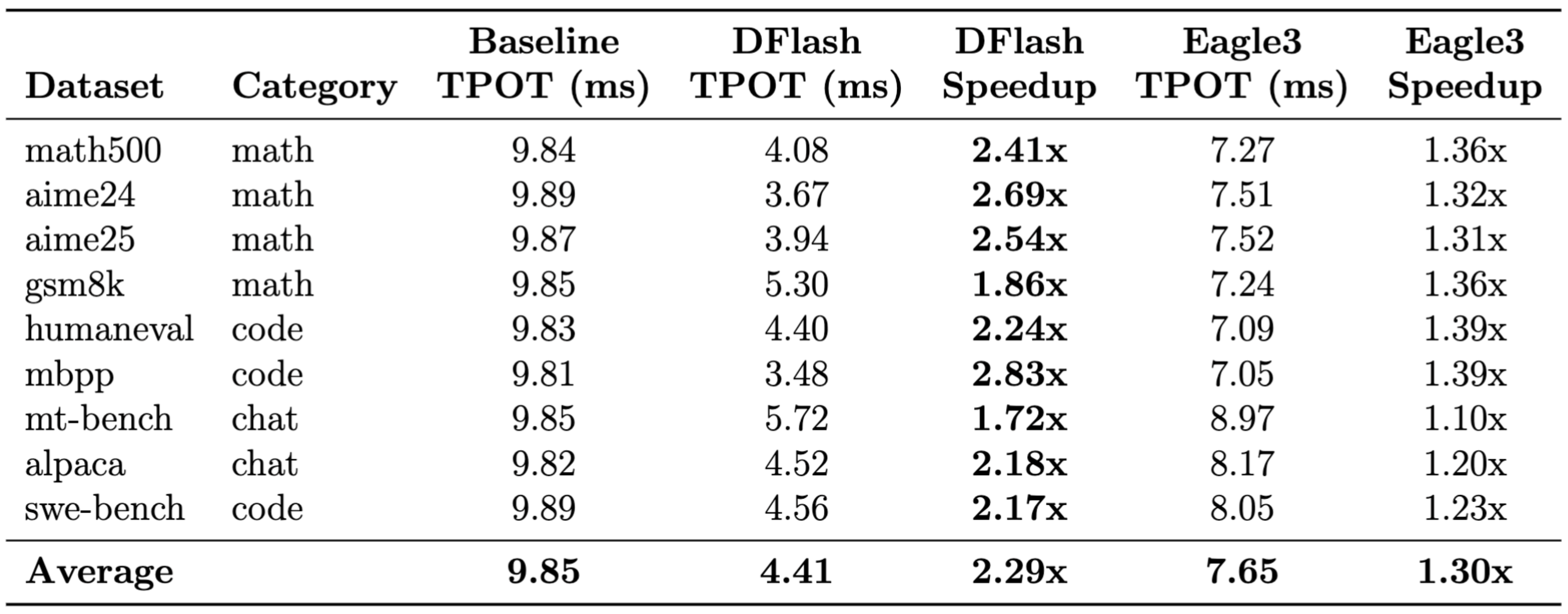
vLLM TPU 파이프라인 및 v5p TPU에서 DFlash vs. Eagle3 모델: Llama-3.1-8B-Instruct (타겟) + z-lab/LLaMA3.1-8B-Instruct-DFlash-UltraChat (DFlash 초안, K=10) / yuhuili/EAGLE3-LLaMA3.1-Instruct-8B (EAGLE-3 초안, K=2)
이 설정은 두 방법 모두에게 가장 실용적인 배포 시나리오를 나타내요. K 값의 선택은 추가 파인튜닝이나 재구성을 거치지 않은, 해당 공식 오픈소스 체크포인트를 기반으로 했답니다. EAGLE-3와 같은 자기회귀 초안 생성기는 K에 비례하여 순차적 레이턴시 패널티를 발생시키기 때문에, 일반적으로 토큰당 레이턴시를 낮게 유지하기 위해 더 작은 투기 예산에 제약을 받아요. 반대로 DFlash는 병렬 블록 확산을 사용하여 단일 정방향 패스에서 모든 토큰을 예측하므로, 초안 생성 비용이 K에 크게 영향을 받지 않아요. 결과는 결정적이었어요. DFlash는 2.29배의 속도 향상을 달성한 반면, EAGLE-3는 1.30배의 이득을 보였죠. mbpp와 같은 코딩 작업에서는 DFlash가 생성 시간을 토큰당 9.81ms에서 3.48ms로 단축하여 2.83배 개선되었어요.
왜 이렇게 차이가 클까요? EAGLE-3는 각 단계에서 순차적인 정방향 패스를 필요로 하며 Python 오케스트레이션 오버헤드를 수반하면서 단계당 2개의 토큰을 자기회귀적으로 예측해요. 반면 DFlash는 단일 정방향 패스에서 10개의 고품질 후보 토큰 블록을 생성하여 이 순차적 병목 현상을 완전히 제거하죠. TPU에서는 이러한 "고품질, 대량" 초안 출력이 더 높은 평균 승인 길이로 직접 이어져, TPU의 엄청난 컴퓨팅 잠재력을 실제 서빙 처리량으로 전환시켜 준답니다.
TPU v5p 벤치마크 결과
구글 TPU에서 DFlash의 영향을 평가하기 위해, UCSD 팀은 TPU v5p에서 다양한 도메인에 걸쳐 구현 성능을 벤치마킹했어요. 특히 복잡한 추론, 수학, 코딩 등 긴 컨텍스트 생성이 일반적으로 높은 레이턴시를 겪는 영역에 중점을 두었죠.
UCSD 팀은 DFlash 결과를 평가하기 위해 독립형 JAX 벤치마크를 구축했어요. 서빙 계층의 오버헤드를 제거함으로써, DFlash-on-TPU 알고리즘의 순수한 성능을 분리할 수 있었어요. 모든 데이터 세트에서 평균 3.13배의 속도 향상을 관찰했으며, 수학적 추론에서는 놀라운 최고치를 기록했답니다.
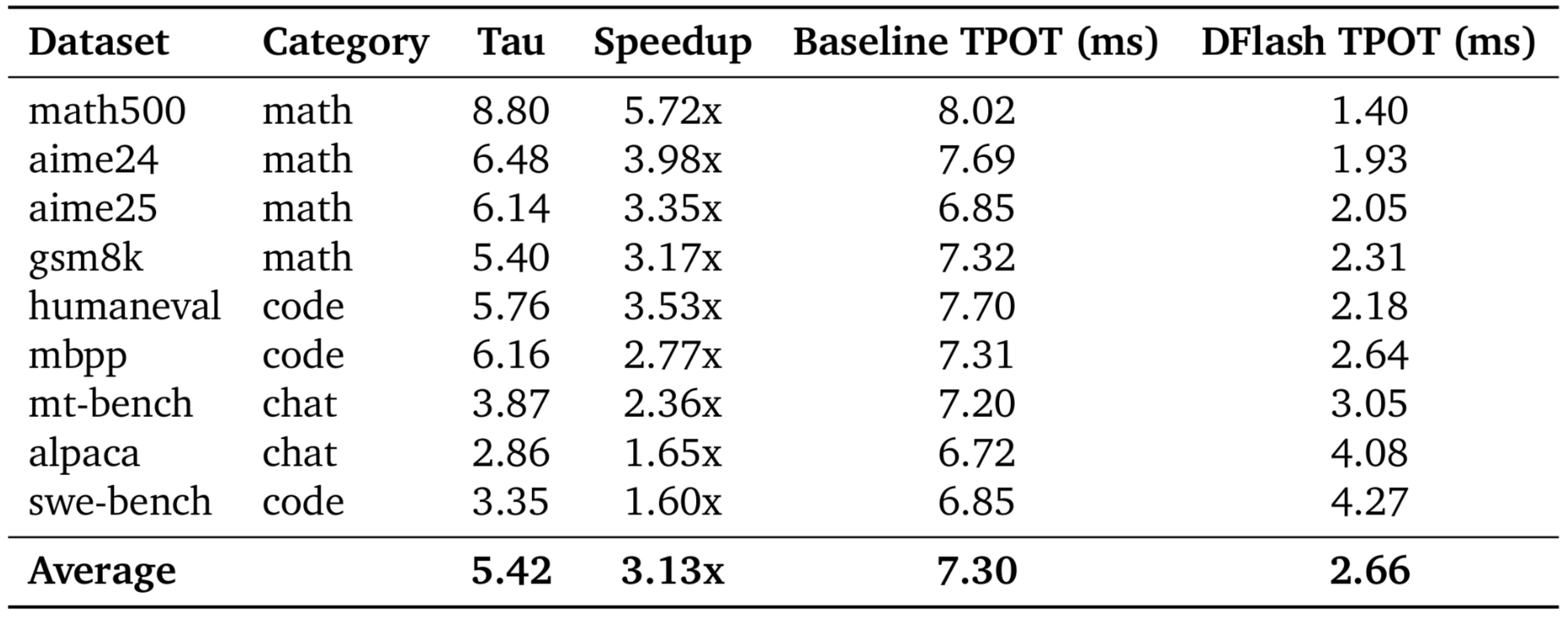
v5p TPU 벤치마크 결과 모델: Qwen/Qwen3-4B (타겟) + z-lab/Qwen3-4B-DFlash-b16 (초안, K=16); 탐욕적 디코딩
_math500_과 같은 엄격한 수학 작업의 경우, DFlash는 생성 시간을 토큰당 8.02ms에서 1.40ms로 단축시켰어요. _humaneval_과 같은 코딩 평가에서는 생성 속도가 3.5배 이상 향상되었죠.
투기적 효율성에 대한 심층 인사이트
"K-Flat" 돌파구: 왜 넓어도 비용이 들지 않는가
최적화 과정에서, 연구팀은 엔지니어들이 투기 한계에 대해 생각하는 방식을 바꾸는 하드웨어 특성인 K-Flat 검증을 발견했어요.
TPU v5p와 같은 데이터센터급 가속기에서, 이들의 체계적인 실험은 놀라운 사실을 밝혀냈어요. 즉, 1024개의 토큰을 검증하는 비용이 단 16개의 토큰을 검증하는 비용과 거의 동일하다는 것이죠. 이러한 현상은 고급 하드웨어에서는 어텐션 메커니즘의 순수 수학 계산보다는 모델 가중치를 로드하는 데 시간이 더 많이 소요되기 때문에 발생해요. 다시 말해, 하드웨어의 계산 한계가 매우 높아서 훨씬 더 긴 "추측"을 확인하는 추가 작업이 본질적으로 거의 "무료"라는 뜻이랍니다.
이 발견은 연구의 모든 전선을 바꾸어 놓았어요. 투기적 디코딩의 병목 현상이 "검증 비용"이 아니라 "초안 품질"임을 증명하는 것이죠. 더 넓은 블록이 계산적으로 무료라는 것을 알게 됨으로써, 개발자들은 하드웨어 속도를 늦출 걱정 없이 초안 블록 크기를 과감하게 확장하여 더 풍부한 양방향 컨텍스트를 활용해 정확도를 향상시킬 수 있게 되었어요.
스케일링 이론: 양보다 질
데이터센터급 AI 가속기가 블록 크기(K)를 늘리는 것을 사실상 "무료"로 만들지만, 스케일링 이론에 따르면 단순히 토큰을 더 추가하는 것은 점진적 이득을 가져올 뿐이라고 해요. 현재 작동 지점에서는 K=16의 블록 크기가 이미 이론적 최대 속도 향상의 90% 이상을 포착하고 있어요. 실제로 K를 16에서 128로 스케일링해도 단계당 추가되는 승인 토큰은 1개 미만일 가능성이 높죠.
진정한 성능 향상 요인은 양보다 질에 있어요. 이들의 분석에 따르면, 위치별 승인 확률(a)을 향상시키는 것이 블록 크기 K를 늘리는 것보다 2~3배 더 가치 있다고 해요. 이는 연구의 초점을 바꾸어 놓았어요. 검증 비용이 일정한 환경에서는, 주요 병목 현상이 시스템이 몇 개의 토큰을 확인할 수 있느냐가 아니라 얼마나 정확하게 예측할 수 있느냐로 바뀌는 것이죠. LLM 서빙의 다음 개척지는 더 넓은 투기 윈도우가 아니라 더 똑똑한 초안 훈련에 달려 있어요.
예측 가능성 요인: 작업별 속도 향상
승인 확률은 작업의 예측 가능성과 깊이 관련되어 있어요. 연구팀은 블록 끝의 토큰이 시작 부분의 토큰보다 추측하기 어렵다는 자연스러운 "위치별 감소(positional decay)" 현상을 관찰했어요. 수학 및 코딩과 같은 논리 중심 분야에서는 이 감소가 현저히 느려, 블록 깊숙이 들어가도 높은 승인율을 유지하죠. 하지만 대화형 채팅은 더 무작위적이며, 처음 몇 토큰 이후에는 정확도가 급격히 떨어져요.
이러한 예측 가능성이 직접적으로 속도 향상을 이끌어내요. 구조화된 추론은 더 예측 가능한 시퀀스를 생성하기 때문에, 수학 및 코드 작업은 훨씬 더 긴 승인 블록을 허용하여 TPU의 병렬 검증 능력을 더 효과적으로 포화시켜요. 결과적으로 DFlash는 수학적 추론에서 가장 큰 이득을 얻고, 코딩이 그 뒤를 따르며, 대화형 작업에서는 더 완만한 개선을 보였답니다.
vLLM과의 오픈소스 통합
이 파트너십의 핵심 원칙은 오픈소스 생태계를 풍요롭게 하는 것이에요. 내부 연구 프로토타입으로만 유지하는 대신, 전체 구현 내용이 vLLM tpu-inference 저장소에 제출되었으며, 다음을 포함해요:
- PR#1868: DFlash 모델 및 제안자 아키텍처.
- PR#1869: 투기적 디코딩을 위한 종단 간 파이프라인 통합.
- PR#1870: 포괄적인 CI 및 종단 간 테스트 프레임워크.
UCSD 팀은 DFlash가 PyTorch 서빙 경로에서도 작동하도록 torchax 제안자를 추가하는 작업을 적극적으로 진행 중이에요.
투기적 시스템의 지평 확장
이 성과는 구글 TPU 혁신의 다음 물결을 위한 토대를 마련했어요. DFlash의 독특한 병렬 샘플링을 활용하여, 투기 캐시를 사용하여 고처리량 환경에서 레이턴시를 획기적으로 줄이는 투기적 투기 디코딩(SSD)을 위한 길을 열고 있어요. 더 풍부한 컨텍스트를 포착하고 복잡한 추론의 승인율을 높이기 위해, TPU RL 스택 Tunix와 MaxText를 사용하여 더 넓은 초안 블록으로 확장할 계획이에요. 또한, 새로 개발된 고성능 JAX 커널은 확산 기반 타겟 모델을 지원하는 기반이 되어, vLLM-TPU 생태계를 효율적인 비자기회귀 생성의 최첨단에 유지하고 있어요.
기반 기술 보고서와 구현 세부 정보는 Colab Notebook에서 검토하거나, vLLM GitHub 저장소에서 직접 코드를 확인해 볼 수 있어요.
연구 제안 모집
이 작업은 TPU Builder 프로그램 덕분에 가능했어요. 이 프로그램은 고성능 하드웨어와 Google Cloud 크레딧에 대한 접근성을 학계 및 오픈소스 커뮤니티에 제공하려는 우리의 사명을 반영하고 있어요. 연구, 교육 또는 오픈소스 개발을 위해 TPU 사용에 관심이 있다면, 구글에게 알려주세요! tpu-builders-support@google.com으로 이메일을 보내 연락해 주세요.
감사의 말씀: Zhongyan Luo, Son Nguyen, Andy Huang을 포함한 UCSD 연구팀에 깊이 감사드립니다. Kyuyeun Kim, Brittany Rockwell, Chris Chan, Mitali Singh, Yixin Shi, Gang Ji 팀에게 PR을 성공적으로 수행하기 위해 연구팀과 협력해 주신 특별한 감사를 전합니다. 또한 Josh Gordon, Edgar Chen, Aditi Joshi, Shubha Rao, Mani Varadarajan, Joe Pamer, Fenghui Zhang, Hassan Sipra, Bill Jia에게 TPU Builder 프로그램의 연구 파트너십에 대한 변함없는 지원과 투자에 감사드립니다.
게시됨:
관련 게시물
 AI 클라우드 튜토리얼 사례 연구 훈련 굿풋(Goodput) 향상: Orbax와 MaxText에서 연속 체크포인팅이 안정성을 최적화하는 방법 2026년 3월 31일
AI 클라우드 튜토리얼 사례 연구 훈련 굿풋(Goodput) 향상: Orbax와 MaxText에서 연속 체크포인팅이 안정성을 최적화하는 방법 2026년 3월 31일 모바일 AI 방법 가이드 모범 사례 온디바이스 AI 가속화: Arm과 Google AI Edge 최적화 살펴보기 2026년 5월 14일
모바일 AI 방법 가이드 모범 사례 온디바이스 AI 가속화: Arm과 Google AI Edge 최적화 살펴보기 2026년 5월 14일 AI 발표 학습 Genkit 미들웨어 발표: 에이전틱 앱을 가로채고, 확장하며, 강화하는 방법 2026년 5월 14일
AI 발표 학습 Genkit 미들웨어 발표: 에이전틱 앱을 가로채고, 확장하며, 강화하는 방법 2026년 5월 14일 페이 모바일 웹 튜토리얼 발표 Google Pay API를 이용한 판매자 주도 거래를 위한 새로운 개선사항 2026년 4월 15일
페이 모바일 웹 튜토리얼 발표 Google Pay API를 이용한 판매자 주도 거래를 위한 새로운 개선사항 2026년 4월 15일
- 연결
* [블로그](https://googledevelopers.blogspot.com/)
* [블루스카이](https://goo.gle/3FReQXN)
* [인스타그램](https://goo.gle/googlefordevs)
* [링크드인](https://goo.gle/gdevs-li)
* [X (트위터)](https://goo.gle/gdevs-tw)
* [유튜브](https://goo.gle/developers)
- 프로그램
* [구글 개발자 프로그램](https://developers.google.com/program)
* [구글 개발자 그룹](https://developers.google.com/community/gdg)
* [구글 개발자 전문가](https://developers.google.com/community/experts)
* [액셀러레이터](https://developers.google.com/community/accelerators)
* [우먼 테크메이커스](https://www.womentechmakers.com/)
* [구글 클라우드 & 엔비디아](https://developers.google.com/community/nvidia)
- 개발자 콘솔
* [구글 API 콘솔](https://console.developers.google.com/)
* [구글 클라우드 플랫폼 콘솔](https://console.cloud.google.com/)
* [구글 플레이 콘솔](https://play.google.com/apps/publish)
* [파이어베이스 콘솔](https://console.firebase.google.com/)
* [액션 온 구글 콘솔](https://console.actions.google.com/)
* [캐스트 SDK 개발자 콘솔](https://cast.google.com/publish)
* [크롬 웹 스토어 대시보드](https://chrome.google.com/webstore/developer/dashboard)
* [구글 홈 개발자 콘솔](https://console.home.google.com/)